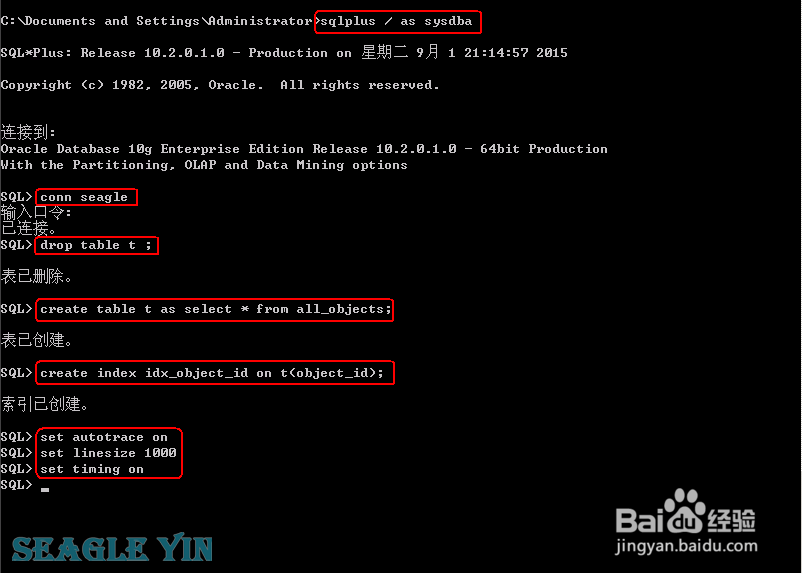
1、构造实验环娓搠础拔境drop table t ;删除现有表,以防影响实际结果create table t as select * from all_objects; 创建表create index idx_object_id on t(object_id); 创建索引set autotrace on 跟踪SQL执行计划和统计信息set linesize 1000 设置显示的行宽set timing on 跟踪SQL执行完成时间
2、第一次执行查询语句select object_name from t where object_id=29;结果:CPU COST 1;52次递归调用;82次逻辑读;4次物理读

3、第二次执行查询语句select object_name from t where obje罕铞泱殳ct_id=2刻八圄俏9;结果:CPU COST 1;0 次递归调用;2 次逻辑读;0 次物理读和第一次查询相比,第二次的代价明显小于第一次,这是因为第一次执行的时候已经将用户连接信息和相关权限信息保存到PGA内存;将SQL解析动作存在了SGA共享池;将数据存在SGA的数据缓冲区。因此,第二次不用递归调用和物理读。

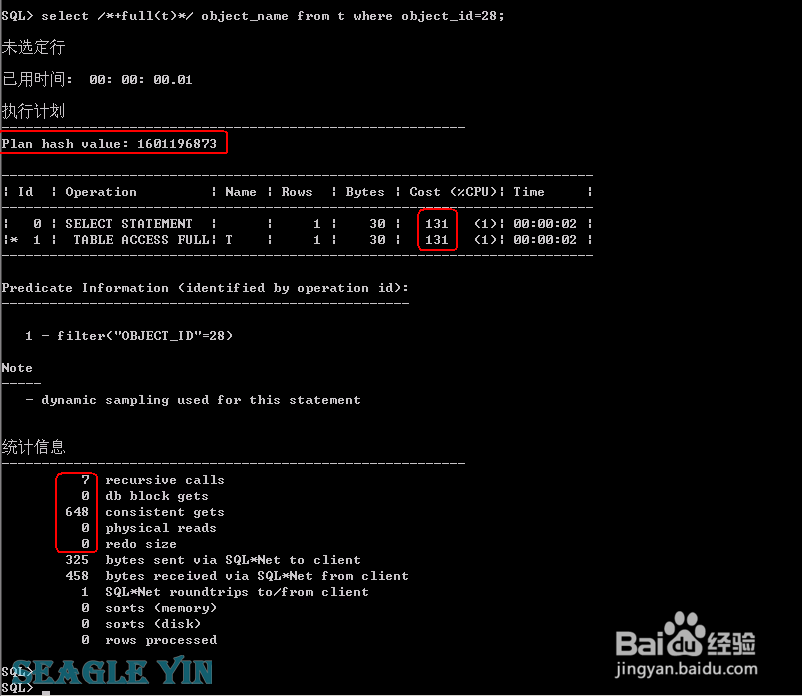
4、重新连接后,第一次故意强制走全表扫描的情况set autotrace onset linesize 1000set timing onselect /*+full(t)*/ object_name from t where object_id=29;结果:CPU COST131;7 次递归调用;648 次逻辑读;0次物理读和走索引相比,HASH 值不一样了,CPU COST 和 逻辑读 明显增加
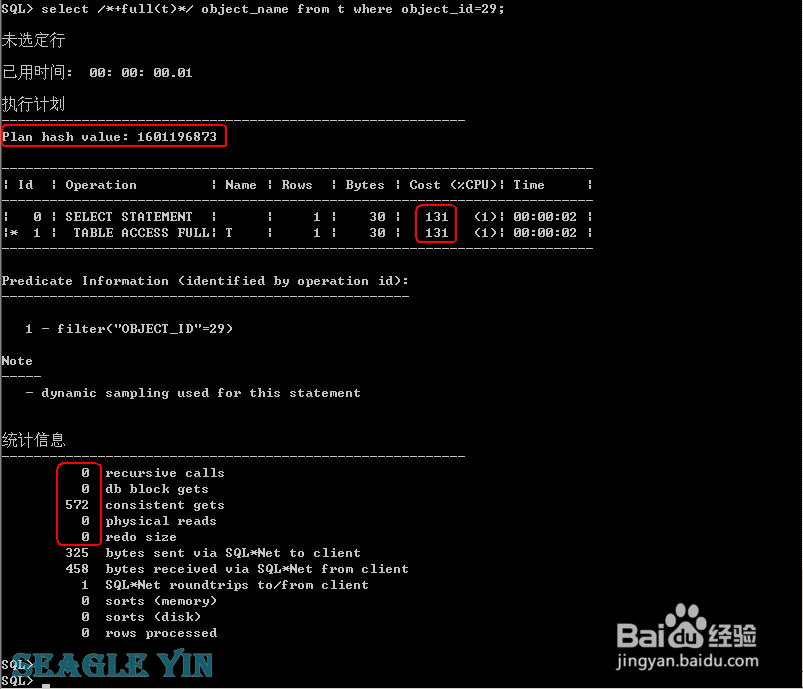
5、第二次故意强制走全表扫描的情况select /*+full(t)*/ object_name from t where object_id=29;结果:CPU COST131;0 次递归调用;572 次逻辑读;0次物理读和走索引相比,HASH 值不一样了,CPU COST和逻辑读明显增加和第一次全表扫描相比,HASH 值一样,递归调用 和 逻辑读 减少