1、首先进行配置分霎霈喊纪布式文件系统,那样就可以提供对应用程序数据的高吞吐量访问支持,设置好java环境后。开始安装Apache Hadoop,创建用于hadoop安装的系统用户帐户。

2、然后需要配置用户hadoop的ssh密钥,使用命令启用无需密码的ssh登录进去,一个基于YARN的大型数据集并行处理系统。

3、接着从官网里面下载hadoop资源包,里面有最新的可用的版本,有时候看个人的需要,最好是下载最新的版本。
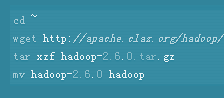
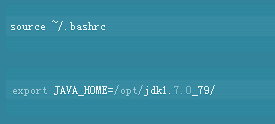
4、然后开始设置hadoop使用的环境变量,编辑~/.bashrc,并在文件末尾添加以下这些值。

5、使用当前运行环境中应用更改,编辑$HADOOP_HOME/etc/hadoop/hadoop-env.sh并设置JAVA_HOME环境变量。
6、最后配置基本的 hadoop 单节点集群开始,编辑hadoop配置文件并进行以下更改,编辑函数core-site.xml启动所有hadoop服务就可以了。

