1、第一步,安装配置好lxml,Windows安装很多坑(自己网上搜吧,有很多问题我也很难解释)。

2、之后,新建py文件,然后把urllib导入,并且还要用到lxml中的etree。

3、之后,自然是用到urlopen发请求到括号里面的地址了哦。并且我们要调用etree里面的HTML方法来接收返回的响应内容,并且保存在page对象里。
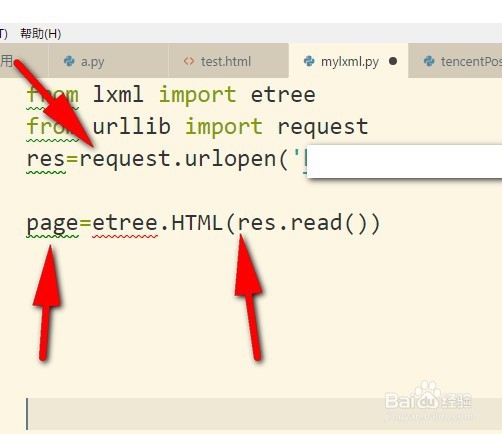
4、page对象可以调用xpath(),然后写上自己的xpath规则就可以了哦,然后我们把解析的内容打印出来看看。

5、如图,运行之后就会解析出内容,xpath得到的结果会是一个列表,也就是带有中括号。

6、如果想去掉中括号,那么可以用[0]来取得里面的元素,当然,一定要保证列表里面有内容才行,不然会报list index out of range之类的错误。。

7、如图,加了index索引之后中括号就去掉了,这样就更加方便我们把内容存放到文件获取数据库里边了。

