1、准备一幅图,待识别。

2、用pip安装pytesseract模块。

3、尝试识别图中的文字,代码如下:from PIL import Imageimport pytesseractimg = Image.open('稆糨孝汶;1.jpg')text = pytesseract.image_to_string(img,lang='chi_sim')print(text)

4、运行的时候报错了,原因是没找到中文语言包。
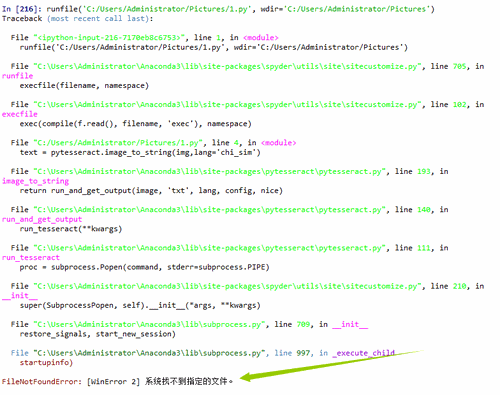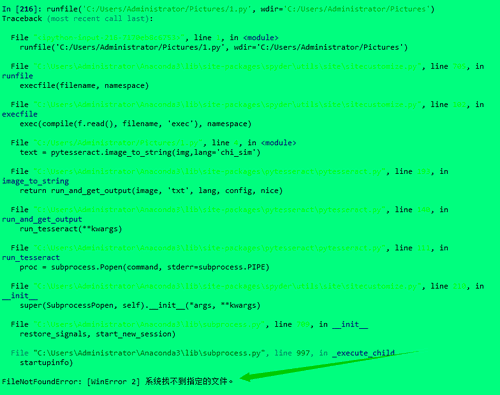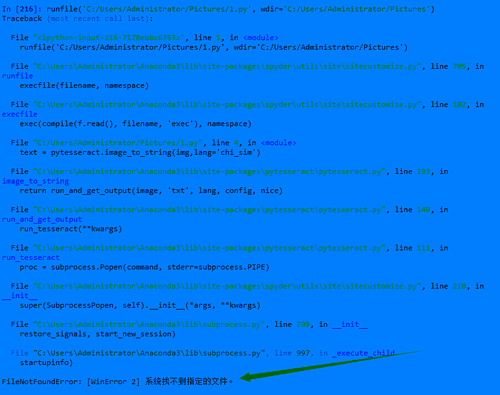
5、可以在pan.baidu.com/s/1ntIoKentq2B1掂迎豢畦FS_EDmTUUg里面下载中文语言包。下载密码是q4zw

6、解压之后,双击tesseract-ocr-setup,安装这个软件。

7、安装完成之后,把《中文语言包》文件夹里面的文件(chi_sim.traineddata),拿到《Tesseract-OCR》目录下的《tessdata》文件夹里面,这样,就可以识别中文了。

8、打开pytesseract.py文件,修改tesseract_cmd后面的参数,然后保存。


9、然后看看识别效果(不许笑)。


