1、创建一个临时表,用于演示如何筛选出表中指定字段值重复的记录数量IF OBJECT_ID(争犸禀淫'tempdb..#tmp1') IS NOT NULL DROP T帆歌达缒ABLE #tmp1;CREATE TABLE #tmp1( Col1 varchar(50), Col2 varchar(200), Col3 int );

2、往临时表中插入几行测试数据,其中部分字段的Col2栏位值插入相同值,用于统计筛选相同Col2的行数insert into #tmp1(Col1荑樊综鲶, Col2, Col3) values('Code1', '语文', 95);insert into #tmp1(Col1, Col2, Col3) values('Code2', '数学', 96);insert into #tmp1(Col1, Col2, Col3) values('Code3', '英语', 92);insert into #tmp1(Col1, Col2, Col3) values('Code4', '语文', 98);insert into #tmp1(Col1, Col2, Col3) values('Code5', '语文', 97);insert into #tmp1(Col1, Col2, Col3) values('Code6', '英语', 92);

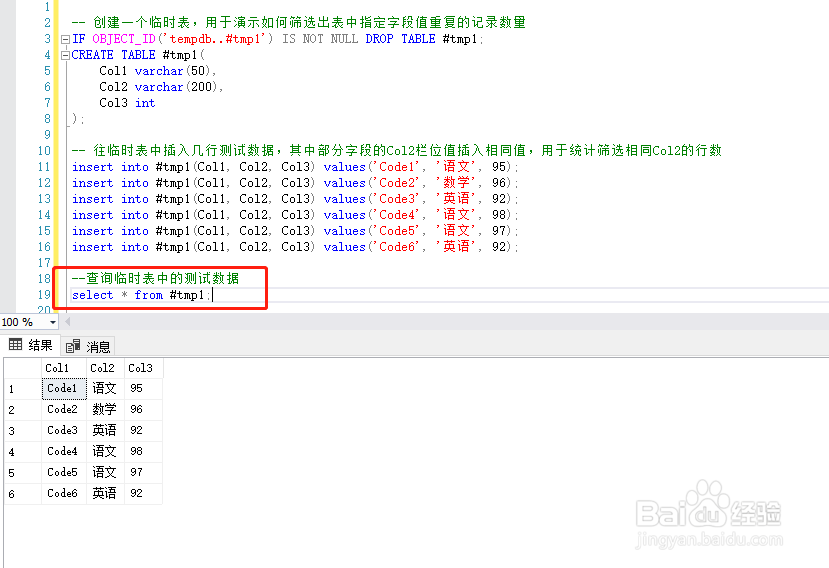
3、查询临时表中的测试数据select * from #tmp1;
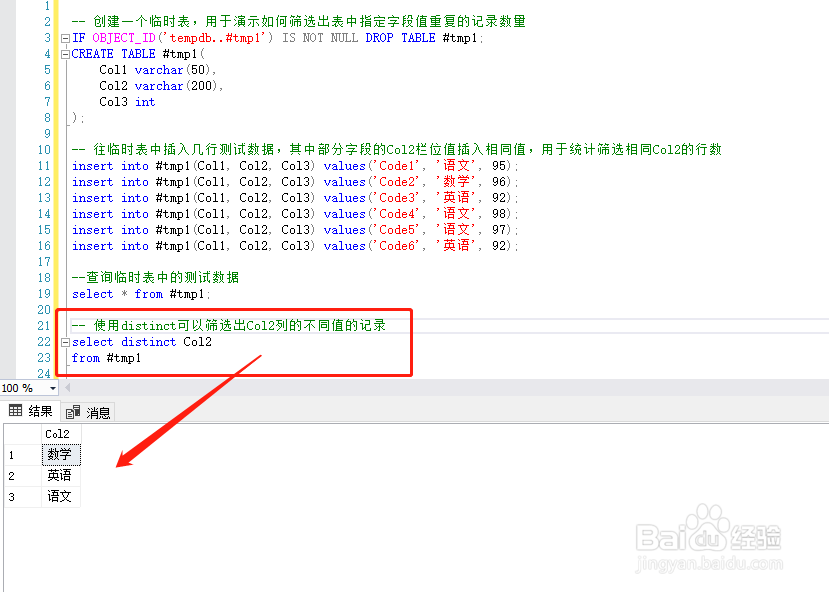
4、使用distinct可以筛选出Col2列的不同值的记录select distinct Col2from #tmp1
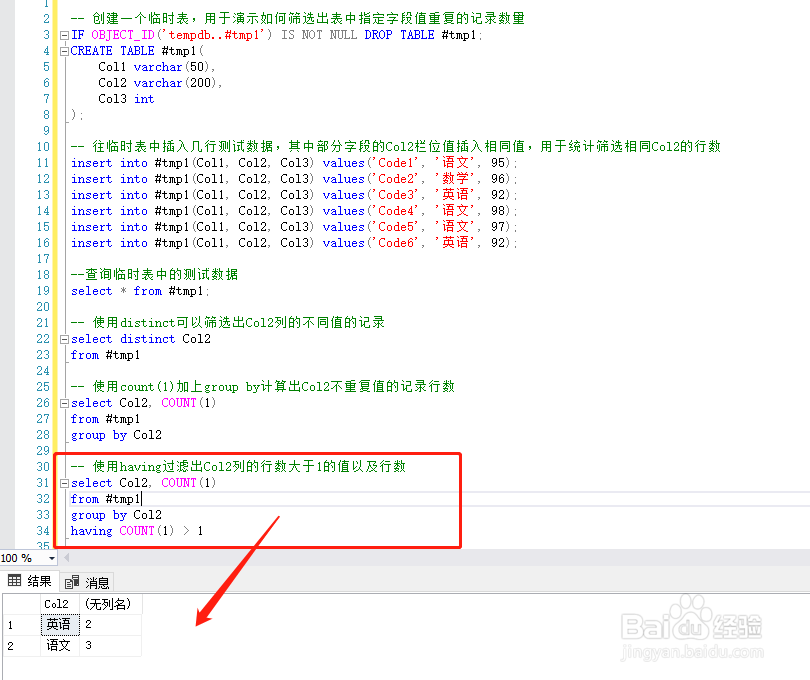
5、使用count(1)加上group by计算出Col2不重复值的记录行数select Col2, COUNT(1)from #tmp1group by Col2

6、使用having过滤出Col2列的行数大于1的值以及行数select Col2, COUNT(1)from #tmp1group by Col2having COUNT(1) > 1
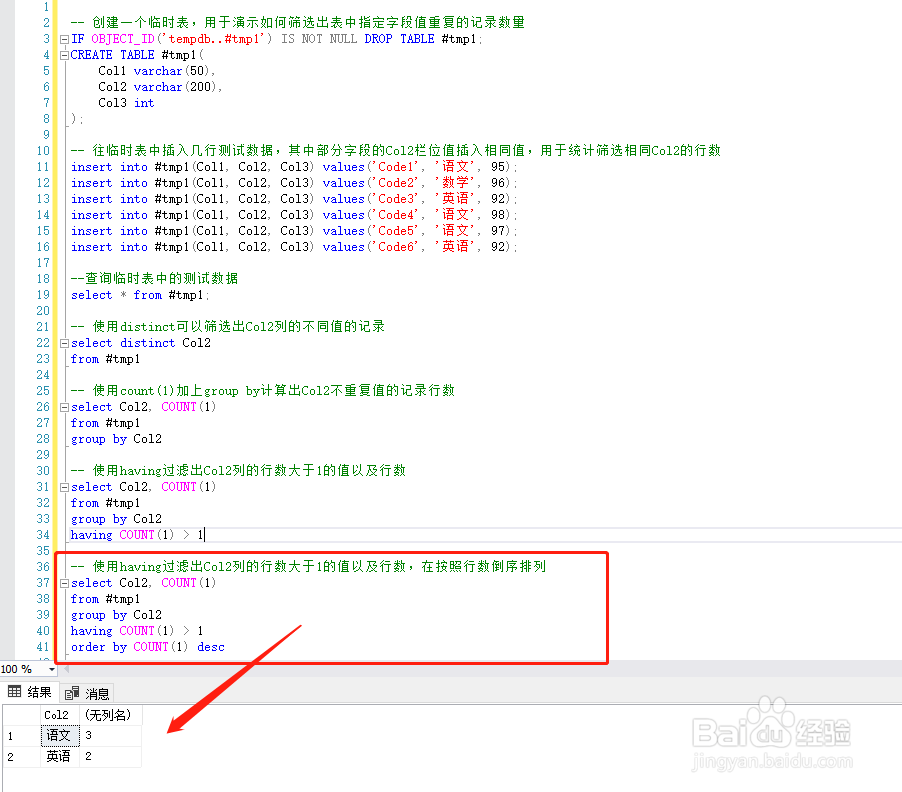
7、使用having过滤出Col2列的行数大于1的值以及行数,在按照行数倒序排列select Col2, COUNT(1)from #tmp1group by Col2having COUNT(1) > 1order by COUNT(1) desc