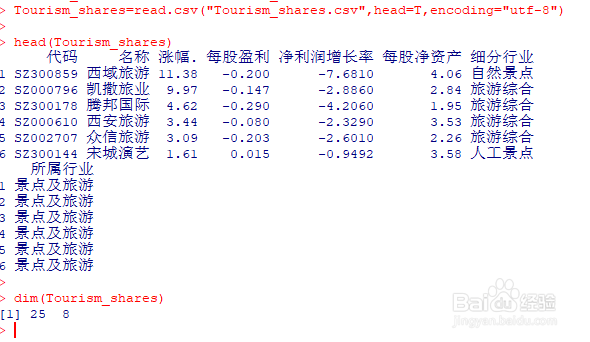
1、读取数据集。Tourism_shares=read.csv("Tourism_shares.csv",head=T,encoding="utf-8")head(Tourism_shares)dim(Tourism_shares)
2、进行聚类分析。libra筠续师诈ry(cluster)#加载软件包fit_pam1=pam(na.omit(Tourism_shares[,3多唉捋胝:6]),k=3)#采用k中心点算法将数据集分为k=3类print(fit_pam1) #输出聚类结果结果中的Medoids指明了具体第几个样本为各类别的中心点。

3、保存每个样本的所属类别。Tourism_shares["K_Medoids_cluster"]=fit_pam1$clusterhead(Tourism_shares)#查看数据和前面的K-means聚类结果对比,可以发现不同样本点在两种算法的聚类结果是有差别的。

4、绘制散点图。plot(Tourism_shares[,3:6],pch=fit_pam1$cluster-1)

