1、一个完整的分词器Analyzer由如下3部分组成:1. Character Filters : 对文本信息就行预处理,比如对原始文本删减或替换字符2. Tokenizer :分词,即将原始文本按照一定规则切分为词语 (term)3. Token Filters : 分词后过滤,对分词后的词语列表进行处理,过滤,删除下面将对这3部分的概念进行一一介绍和演示。
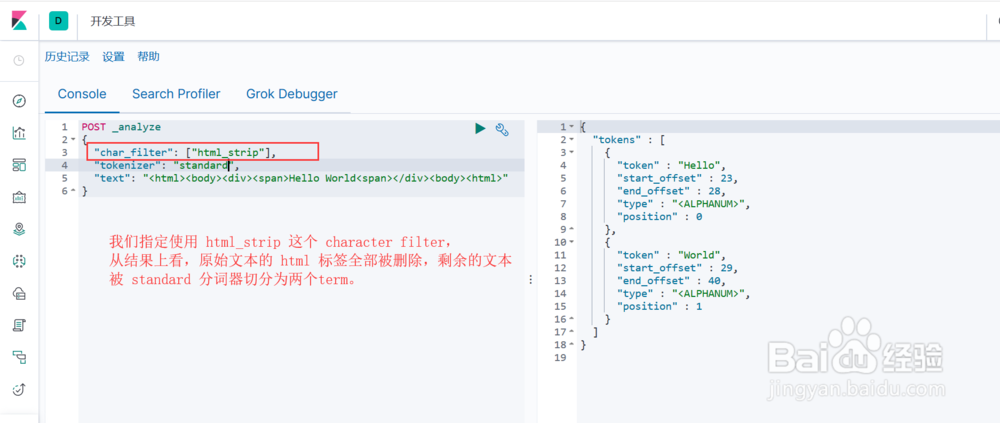
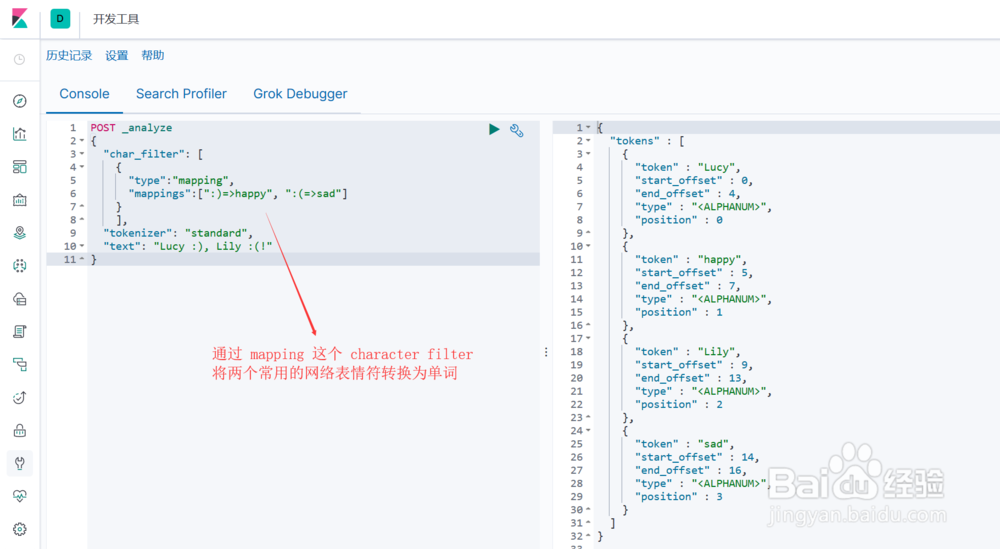
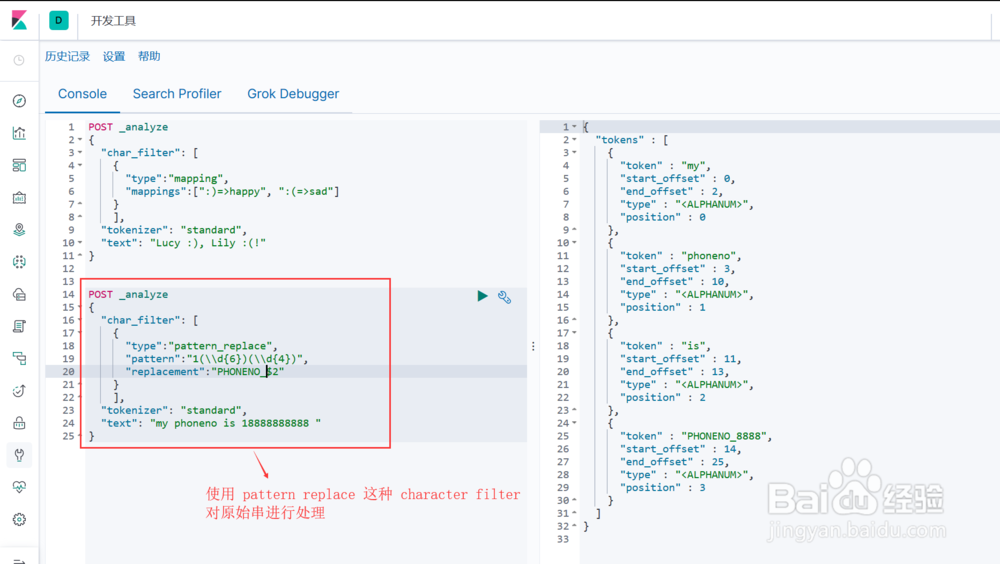
2、Character FiltersES中自带了如下的Character Filters:1. html strip : 去除 html 标签2. mapping : 字符串替换3. pattern replace : 正则匹配替换图1示, html strip 这个 character filter 的使用图2示, mapping 这个 character filter 的使用图3示, pattern replace 这个 character filter 的使用
3、TokenizerES中自带了这些 Tokenizer ,如 whitespace (空格) , standard (空格), uax_url_email (url邮件), pattern (正则), keyword (不切词) ,path_hierarchy(文件路径目录)等图示,path_hierarchy 这个内置的 tokenizer 的使用,会把一个完整路径按每级目录进行切分

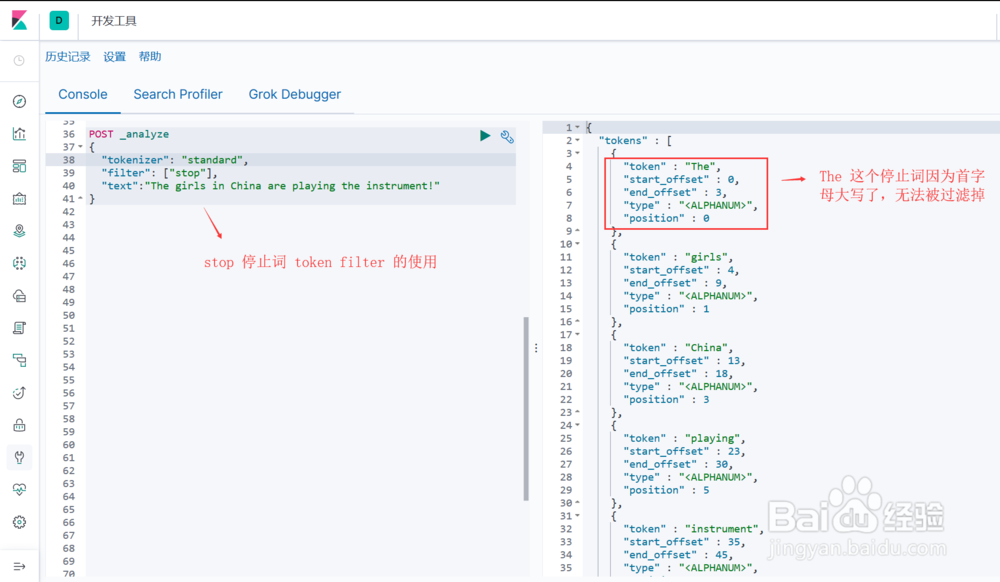
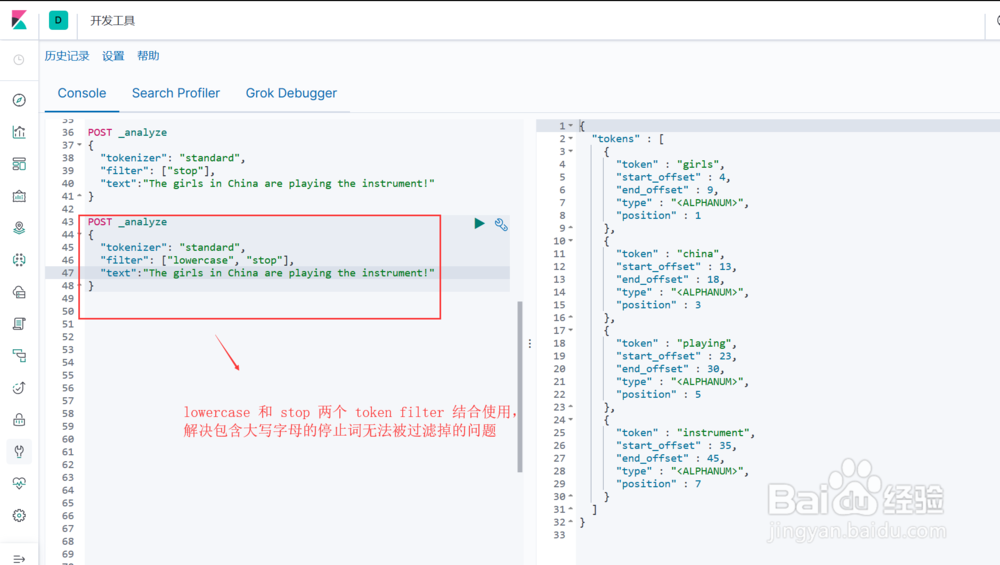
4、Token Filters对 Tokenizer 分词后的结果进行再加工,腻戴怯猡包括字符处理,过滤,删除等操作,ES内置的 Token Filters 包括 : lowercas髫潋啜缅e (转小写), stop (删除停止词) , synonym (添加同义词)图1示, stop 这个 token filter 的使用,注意默认停止词列表全是小写词语,也就是说,单词 “The”虽然是停止词,但因为第一个字符是大写的,单独使用 stop 这个 token filter 无法将其过滤掉。图2示,lowercase 和 stop 两个 token filter 结合使用,可以解决图1示例的问题
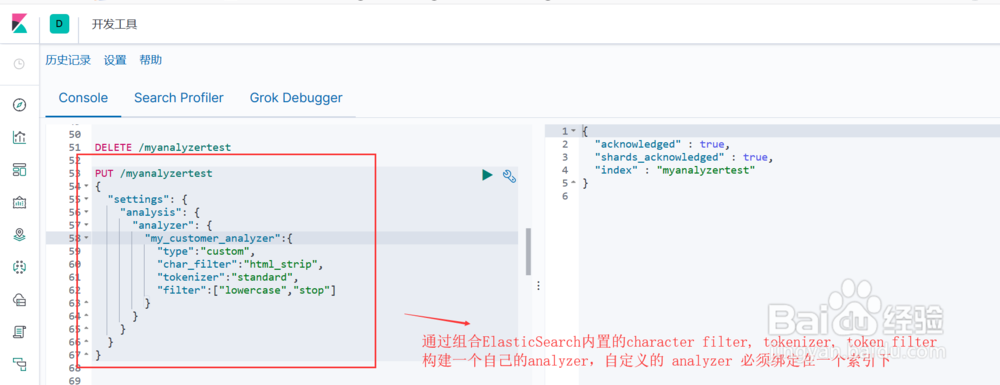
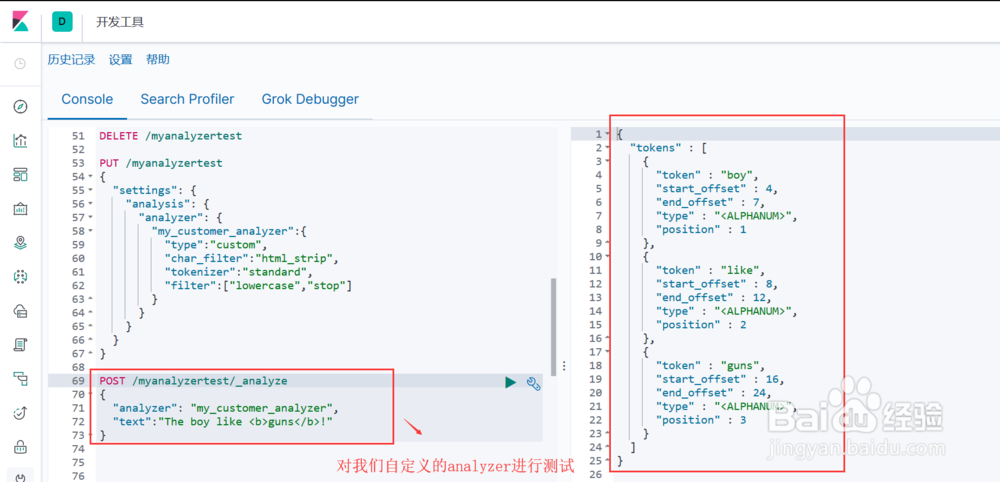
5、在索引中自定义简单的分词器 Analyzer上面各个步骤介绍了Analyzer的构成,以及ElasticSearch为每一部分所提供的默认实现,通过组合这些默认实现,我们可以构建属于自己的 Analyzer。自定义的 Analyzer 必须关联到一个索引上,其语法格式如下:PUT 索引名称{"settings": { "analysis": { "analyzer": { "自定义分词器名称":{ 自定义分词器具体内部实现 } } } }}图1示,我们通过组合 html strip (character filter), standard (tokernizer), lowercase stop (token filter) 来实现自己的分词器图示2, 测试我们自己的分词器