1、比如我们需要爬虫一个招聘网站上的相关招聘信息,来用作我们之后的处理和操作的话,我们需要先右键当前网页,来查看我们的网页源代码。可以看见,下图就是我们网页源代码的一部分。
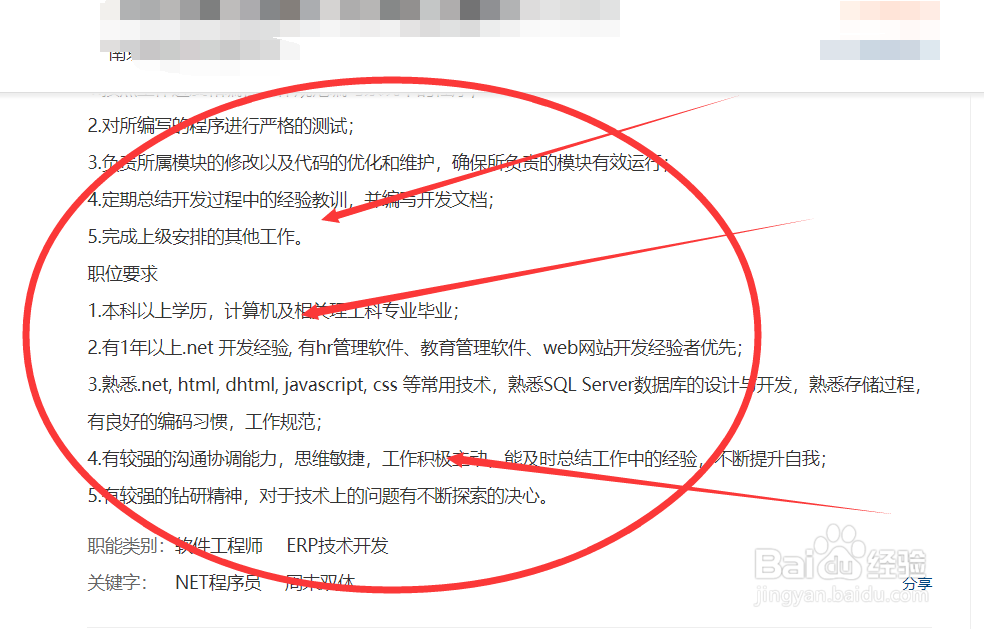
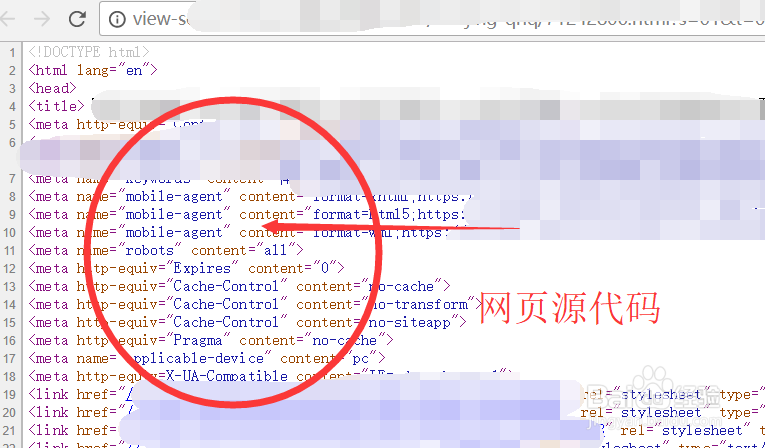
2、然后我们需要翻阅源代码,来看到我们需要爬虫的相关内容,我们可以看到,我们需要的相关内容全部被<p>....</p>标签所包围,因此我们初步采用的正则表达式肯定就是包含有p标签的筛选。

3、但是在这里我们需要注意的是,直接通过<p>这样子筛选是很有可能又弊端的,因为html的标签之中,<p class="???">这样子的标签也是很常见的,这样子仅仅要通过<p>这样子筛选是肯定会漏掉的,因此我们拟采用<p.*?>.*?</p>这个方法来进行筛选,别的标签比如div span 也是同理。

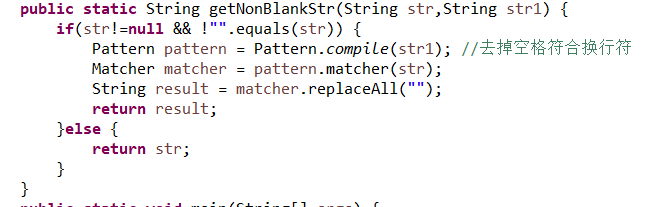
4、接下来我们使用java爬虫的方式来测试一下我们爬出来的结果,当然python爬虫也是一样的,我们写上我们需要的正则之后,就可以爬出我们相应的结果了,可以看到,其中的内容要比我们想要的内容多,我们只需要<p>这样的标签之后加上1.这样子的格式的就行了,因此我们需要更改我们的正则表达式。
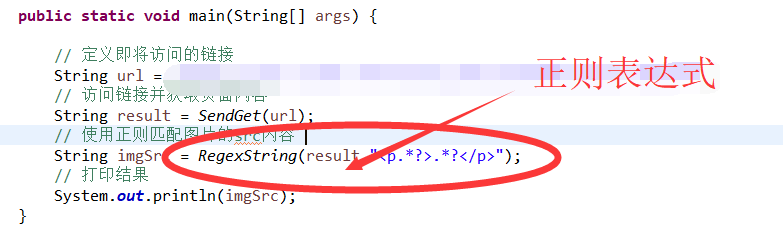
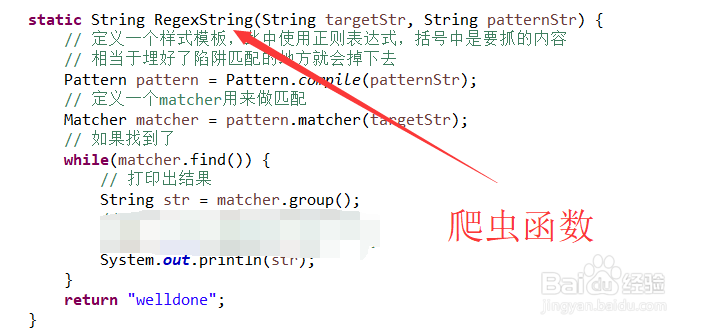
5、<p>[0-9][.]{1}.*?</p>这个就是我们最终选用的正则表达式,这个用来匹配我们的1. 2. 3. 这样子格式的文件,可以看到匹配结果很令人满意,它成功的筛选了所有我们的需要的内容。


6、最后一步,我们就是要去掉这个两边的<p>...</p>符号,使其变为一个纯文本文件。我们使用的正则表达式为<[/]{0,1}p>这样就可以完美的去掉<p>...</p>是不是很简单呢?