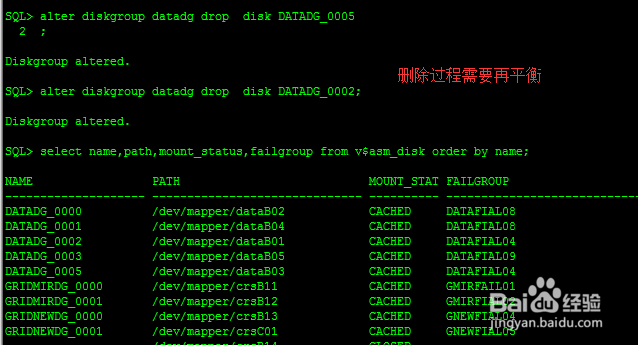
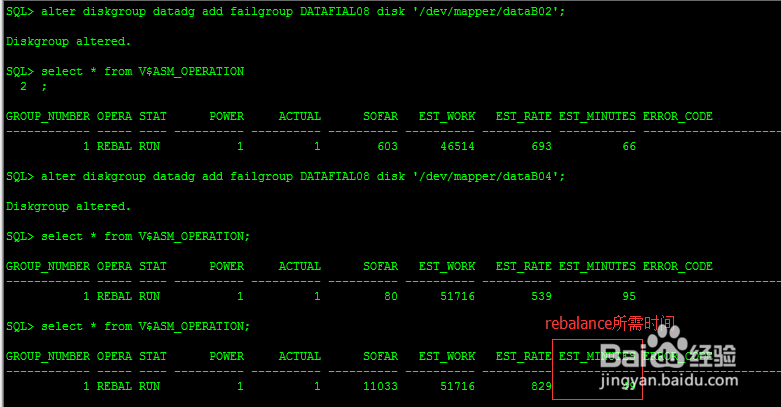
1、1:添加新的FAILGROUPSQL> select name,path,mount_status,failgroup from v$asm_disk order by name;NAME PATH MOUNT_STAT FAILGROUP-------------------- ------------------------------ ---------- ------------------DATADG_0002 /dev/mapper/dataB01 CACHED DATAFIAL04DATADG_0005 /dev/mapper/dataB03 CACHED DATAFIAL04GRIDMIRDG_0000 /dev/mapper/crsB11 CACHED GMIRFAIL01GRIDMIRDG_0001 /dev/mapper/crsB12 CACHED GMIRFIAL02GRIDNEWDG_0000 /dev/mapper/crsB13 CACHED GNEWFIAL04GRIDNEWDG_0001 /dev/mapper/crsC01 CACHED GNEWFIAL05_DROPPED_0003_DATADG MISSING DATAFIAL07_DROPPED_0004_DATADG MISSING DATAFIAL07目前DATADG存放数据文件(冗余策略--标准冗余策略),且DATADG有两个FAILGROUP:DATAFIAL07和DATAFIAL04。从上面可以发现DATAFIAL07中的磁盘都已经失效了。由于DATADG采用标准模式,一个FAILGROUP失效不会影响到数据库。所以现在需要立马添加一组FAILGROUP来恢复DATADG冗余策略,防止DATAFIAL04失效导致数据库宕机。现在我们来添加磁盘:alter diskgroup datadg add failgroup DATAFIAL08 disk '/dev/mapper/dataB02';alter diskgroup datadg add failgroup DATAFIAL08 disk '/dev/mapper/dataB04';alter diskgroup datadg add failgroup DATAFIAL09 disk '/dev/mapper/dataB05';当然我们也可以通过添加丢失磁盘来检测磁盘是否正在丢失:SQL> alter diskgroup datadg add failgroup DATAFIAL08 disk '/dev/mapper/dataA01';ERROR at line 1:ORA-27061: waiting for async I/Os failedLinux-x86_64 Error: 5: Input/output errorAdditional information: -1注意:这里添加了两个新的FAILGROUP。因为如果想要删除旧FAILGROUP DATADG必须保留两个FAILGROUP。

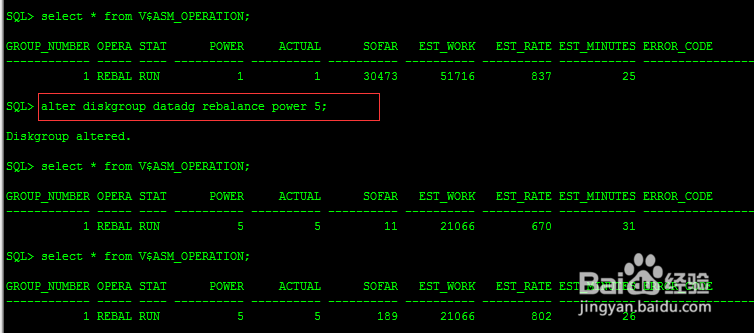
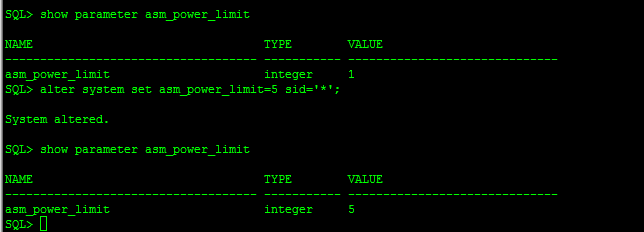
2、查看rebalanceSQL> select * from V$ASM_OPERATION;GROUP_NUMBER OPERA STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE------------ ----- ---- ---------- ---------- ---------- ---------- ---------- ----------- -------------------------------------------- 1 REBAL RUN 1 1 11033 51716 829 49SQL> show parameter asm_power_limitNAME TYPE VALUE------------------------------------ ----------- ------------------------------asm_power_limit integer 1从中可以看出,默认rebalance采用POWER 1,ASM_POWER_LIMIT:指定磁盘rebalance的程度,有0-11个级别,默认值为1,指定的级别越高,则rebalance的操作就会越快被完成(当然这也意味着这个时间段内将占用更多的资源),指定级别较低的话,虽然rebalance操作会耗时更久,但对当前系统的IO及负载影响会更少如果想加快再平衡速度。可以更改dg power:SQL> alter diskgroup datadg rebalance power 5;手动平衡磁盘组可能涉及大量的工作,该操作可能费时较久,一定要注意该操作对IO性能的影响。另外再次强调,上述语句将很快返回diskgroup altered的提示,但这并不表示操作真正完成,它只是反馈语句提交而已,查看磁盘后台的操作,可以通过v$asm_operator视图,或者在语句执行时增加wait子句,这样ASM将会等到操作真正完成时,才返回提示信息。当然可以可通过更改ASM默认SQL> alter system set asm_power_limit=5 sid='*';只需要在一个节点执行即可
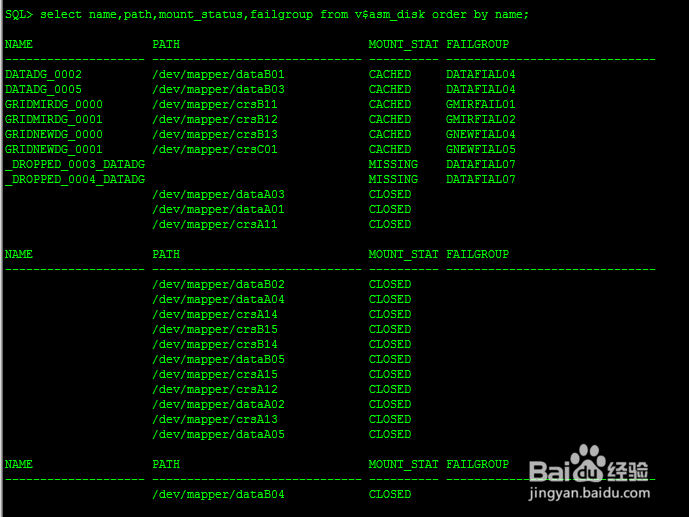
3、3:删除旧FAILGROUPSQL> select name,path,mount_status,failgroup from v$asm_disk order by name;NAME PATH MOUNT_STAT FAILGROUP-------------------- ------------------------------ ---------- ------------------------------DATADG_0000 /dev/mapper/dataB02 CACHED DATAFIAL08DATADG_0001 /dev/mapper/dataB04 CACHED DATAFIAL08DATADG_0002 /dev/mapper/dataB01 CACHED DATAFIAL04DATADG_0003 /dev/mapper/dataB05 CACHED DATAFIAL09DATADG_0005 /dev/mapper/dataB03 CACHED DATAFIAL04GRIDMIRDG_0000 /dev/mapper/crsB11 CACHED GMIRFAIL01GRIDMIRDG_0001 /dev/mapper/crsB12 CACHED GMIRFIAL02GRIDNEWDG_0000 /dev/mapper/crsB13 CACHED GNEWFIAL04GRIDNEWDG_0001 /dev/mapper/crsC01 CACHED GNEWFIAL05这里因为datadg是标准冗余策略,已经有三个FAILGROUP,必须留下两个FAILGROUP,可以删除旧的FAILGROUP。删除FAILGROUP的步骤:一个个删除该FAILGROUP中磁盘即可SQL> alter diskgroup datadg drop disk DATADG_0005;SQL> alter diskgroup datadg drop disk DATADG_0002;如果想回退删除操作:SQL> alter diskgroup datadg undrop disks; 如果再平衡操作完成,那么回退操作是无效的。