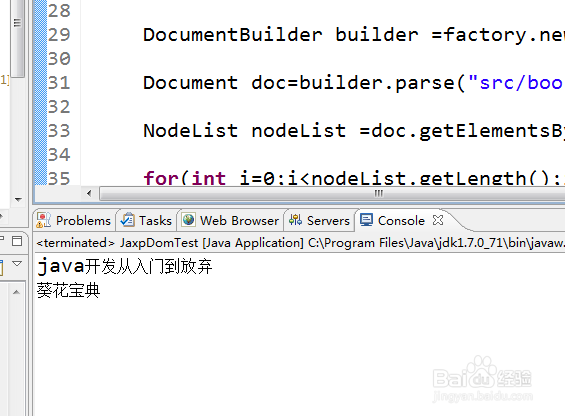
1、第一通过DocumentBuilderFactory的newInstance()方法得到一个工厂对象。
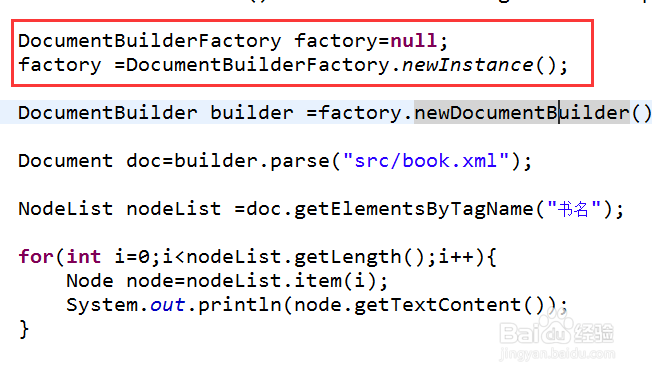
2、第二利用得到的工厂对象调用newDocumentBuilder()获取一个解析器对象。

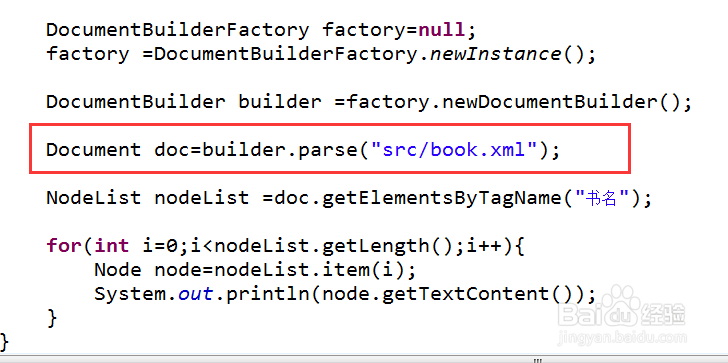
3、然后利用解析器去解析资源文件,得到整个文档对象。
4、然后就可以利用getElementByTagName(String name)方法得到一个节点集合。这里的话当然name=书名

5、遍历集合,然后利用NodeList的item(int index)方法得到一个具体节点,再调用它的getTextContent()获得相应的文本内容。

6、运行就可以得到结果,和xml中相应的内容是一致的。