1、首先,并发性上不去是因为当多个线程同时访问一行数据时,产生了事务,因此产生写锁,每当一个获取了事务的线程把锁释放,另一个排队线程才能拿到写锁,QPS(Query Per Second每秒查询率)和事务执行的时间有密切关系,事务执行时间越短,并发性越高,这也是要将费时的I/O操作移出事务的原因。

2、然后,红色的部分就表示会发生高并发的地方,绿色部分表示对于高并发没有影响。这是为了我们的秒杀系统的优化做铺垫,比如在秒杀还未开始的时候,用户大量刷新秒杀商品详情页面是很正常的情况,这时候秒杀还未开始,大量的请求发送到服务器会造成不必要的负担。

3、然后,将这个详情页放置到CDN中,这样用户在访问该页面时就不需要访问我们的服务器了,起到了降低服务器压力的作用。而CDN中存储的是静态化的详情页和一些静态资源(css,js等),这样我们就拿不到系统的时间来进行秒杀时段的控制,所以我们需要单独设计一个请求来获取我们服务器的系统时间。

4、然后,获取系统时间不需要优化,因为Java访问一次内存(Cacheline)大健懔惋菹约10ns,1s=10亿ns,也就是如果不考虑GC,这个操作1s可以做1亿次。秒杀地址接口分析,无法使用CDN缓存,因为CDN适合请求对应的资源不变化的,比如静态资源、JavaScript;秒杀地址返回的数据是变化的,不适合放在CDN缓存;适合服务端缓存:Redis等,1秒钟可以承受10万qps。多个Redis组成集群,可以到100w个qps. 所以后端缓存可以用业务系统控制。
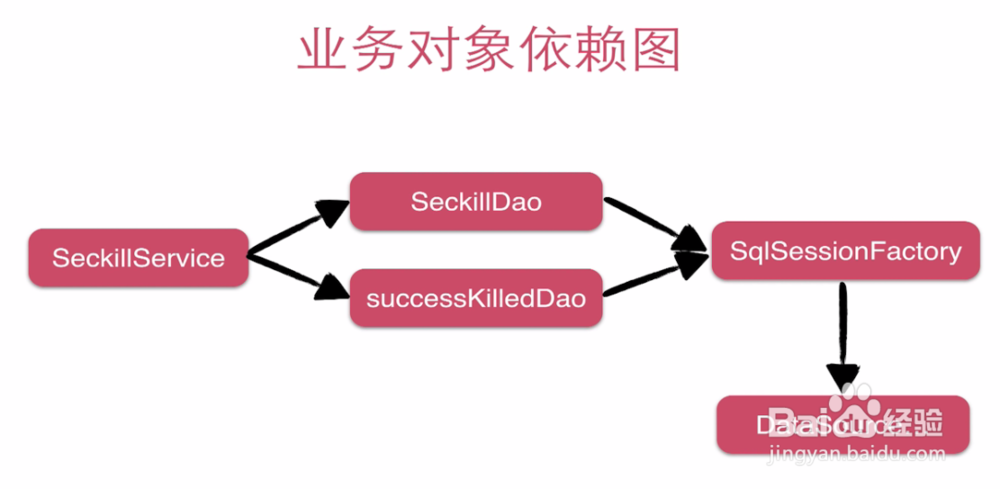
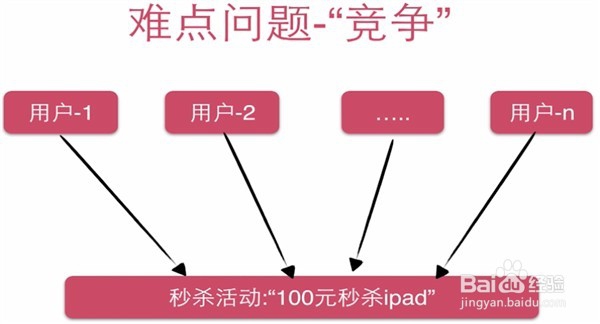
5、然后,大部分写的操作和核心操作无法使用CDN,也不可能在缓存中减库存。你在Re蟠校盯昂dis中减库存,那么用户也可能通过缓存来减库存,这样库存会不一致,所以要通过mysql的事务来保证一致性。比如一个热点商品所有人都在抢,那么会在同一时间对数据表中的一行数据进行大量的update set操作。行级锁在commit之后才释放,所以优化方向是减少行级锁的持有时间。
6、最后,定制SQL方案,在每次update后都会自动提交,但需要修改MySQL源码,成本很高,不是大公司(BAT等)一般不会使用这种方法。使用存储过程:整个事务在MySQL端完成,用存储过程写业务逻辑,服务端负责调用。

