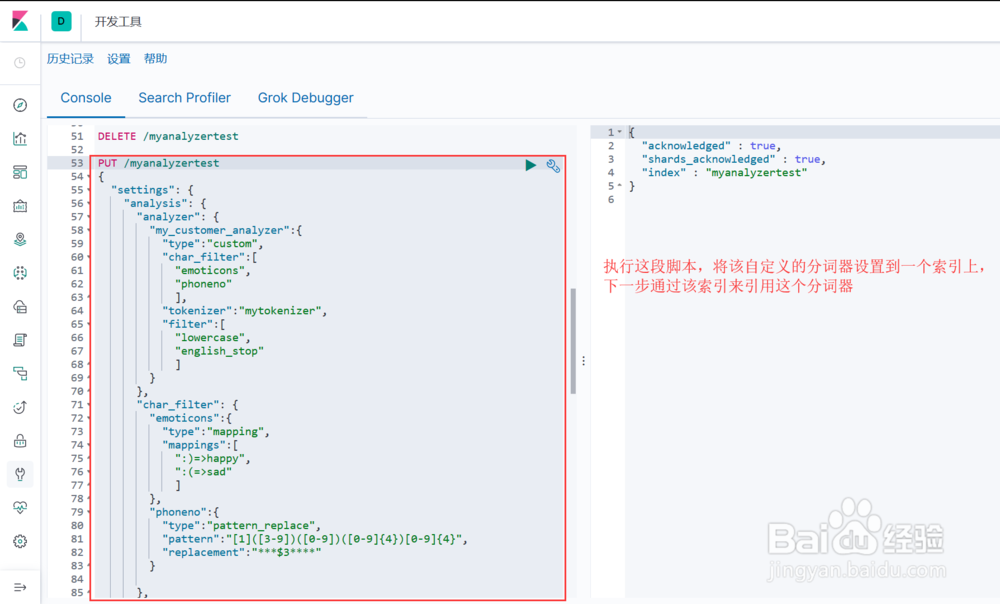
1、首先看一下实现一个 character filter, tokenizer, token filter 三部分全部自定义的分词器Analyzer的相关语法结构。
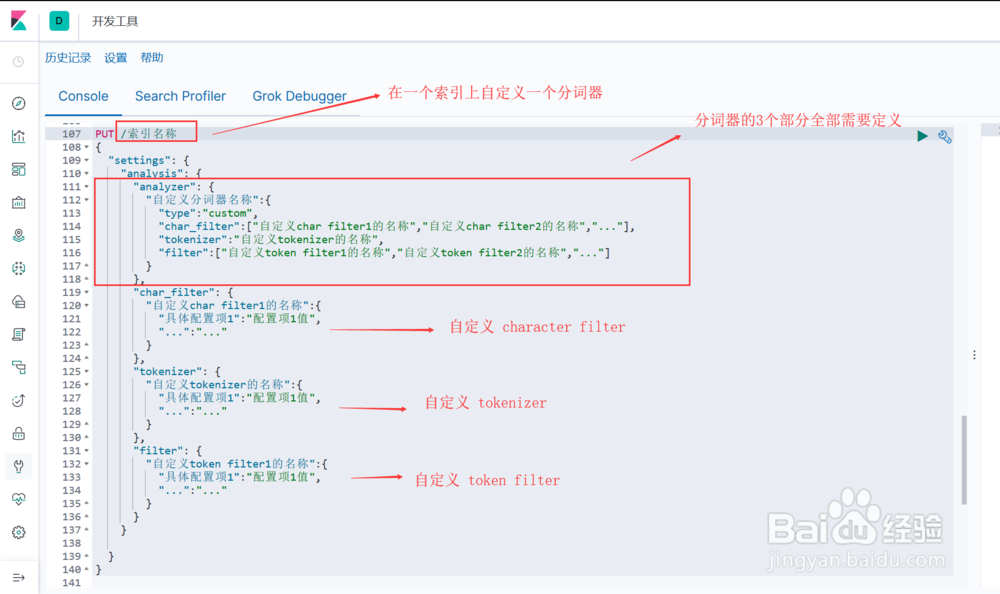
2、实现自定义的 character filter , 语法结构为:"char_filter": { "自定义char filter的名称":{ "配置项1":"配置项1值", "配置项2":"配置项2值", "...":"..." } }图1示:定义一个 mapping 类型的 character filter,处理表情字符图2示:定义一个 pattern replace 类型的 character filter,处理手机号码


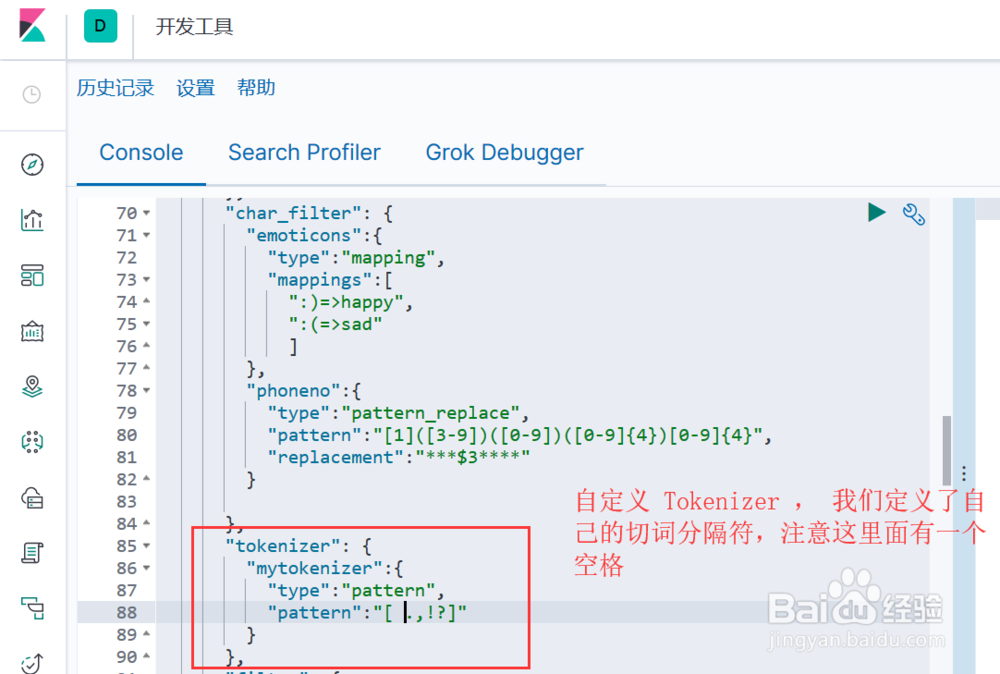
3、实现自定义的 Tokenizer, 语法结构为:"tokenizer": { "自定义tokenizer的名称":{ "配置项1":"配置项1值", "配置项2":"配置项2值", "...":"..." } }图示,定义了一个正则类型的 Tokenizer, 指定了若干个分词字符
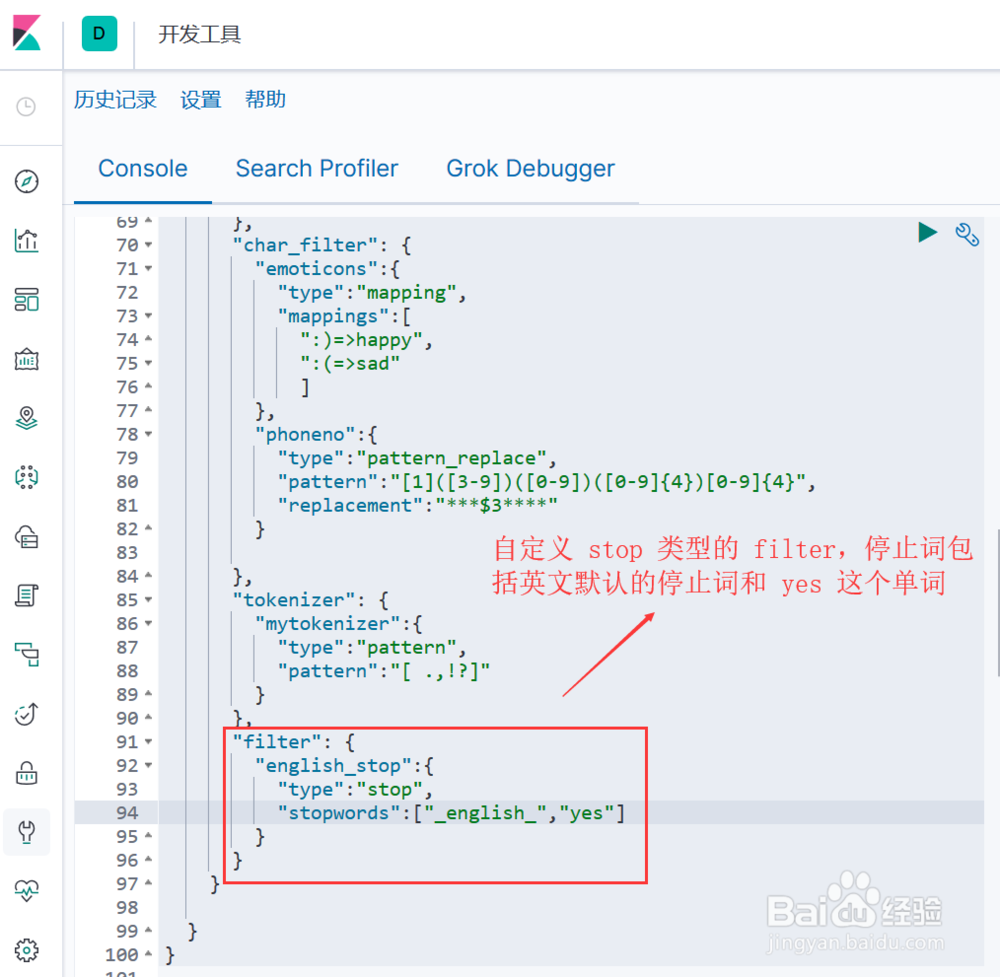
4、实现自定义的 Token Filter, 语法结构为:"filter": { "自定义token filter的名称":{ "配置项1":"配置项1值", "配置项2":"配置项2值", "...":"..." } }图示,定义一个 stop 类型的 token filter, 停止词除了英文默认的停止词列表(_english_ ,还额外加了一个单词 "yes"
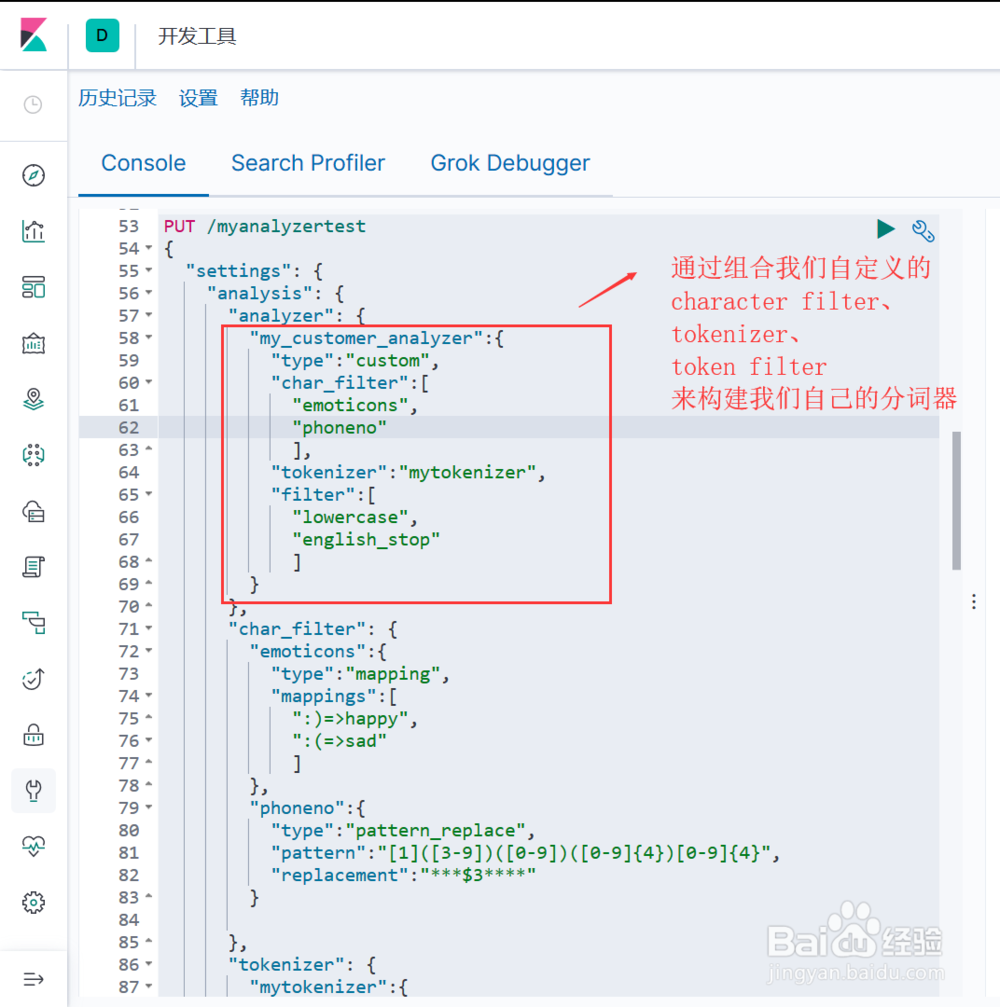
5、通过组合上述自定义的 character_filter、tokenizer、token filter 构建自定义的分词器 analyzer(图示), 语法结构为:"analyzer": { "自定义分词器名称":{ "type":"custom", "char_filter":["自定义char filter的名称","..."], "tokenizer":"自定义tokenizer的名称", "filter":["自定义token filter的名称","..."] } }
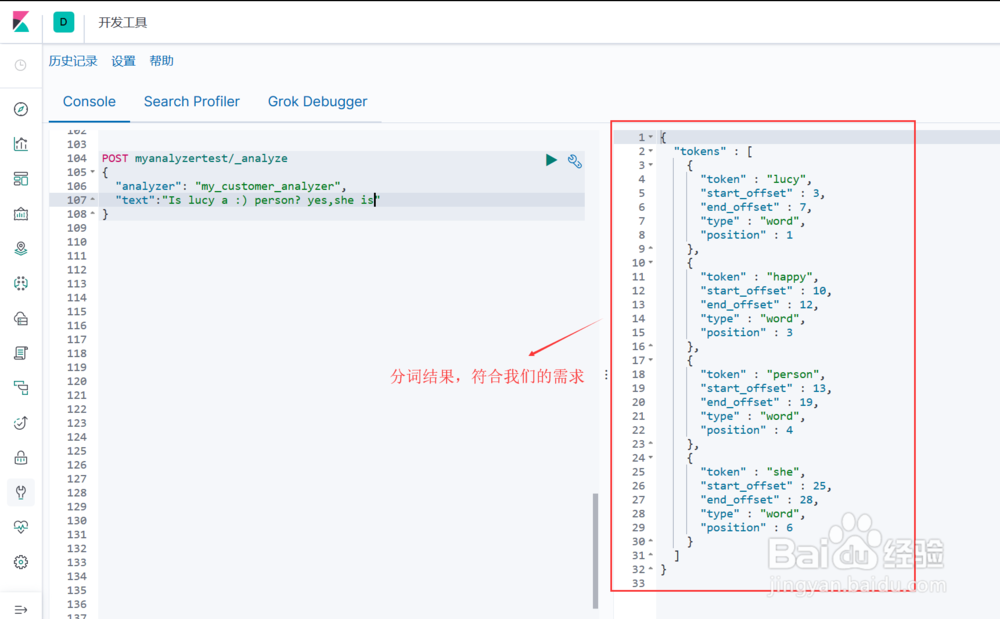
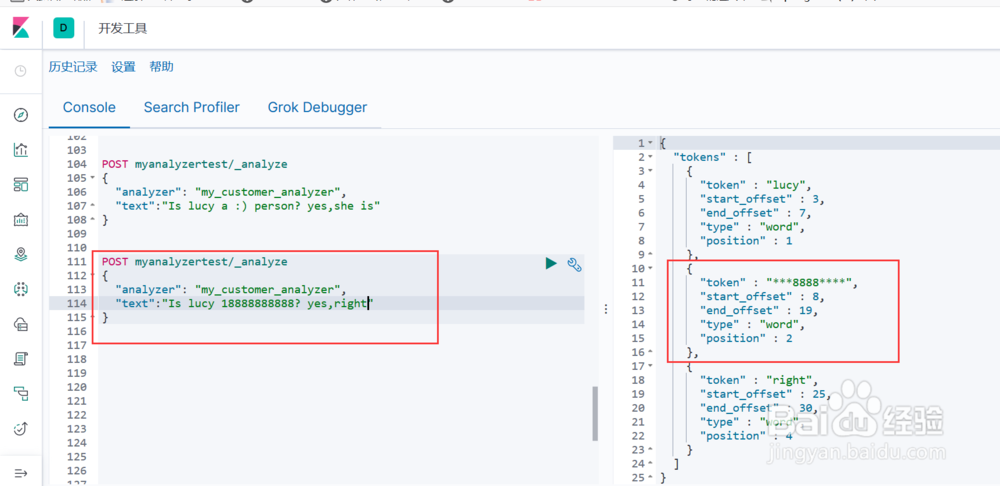
6、测试自定义分词器1. 将该分词器设置到一个索引上(图1示)2. 通过该索引来引用这个分词器进行测试,包含表情符和新停止词(图2示)3. 通过该索引来引用这个分词器进行测试,包含手机号和新停止词(图3示)