1、在百度上搜索CIFAR10,下载适用于python的数据集。

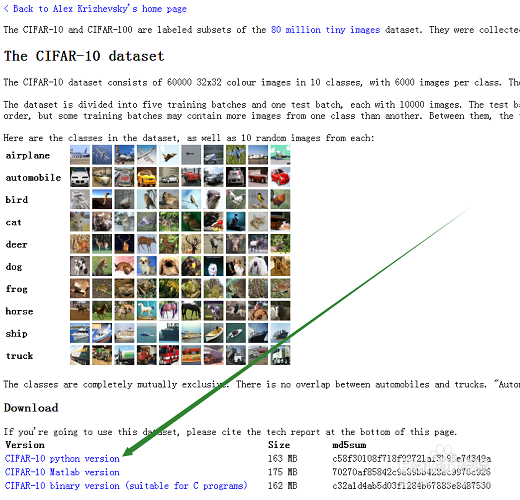
2、把下载的压缩包解压到某个文件夹里面。数据集包括6个文件,其中前五个是训练集,最后一个是测试集。

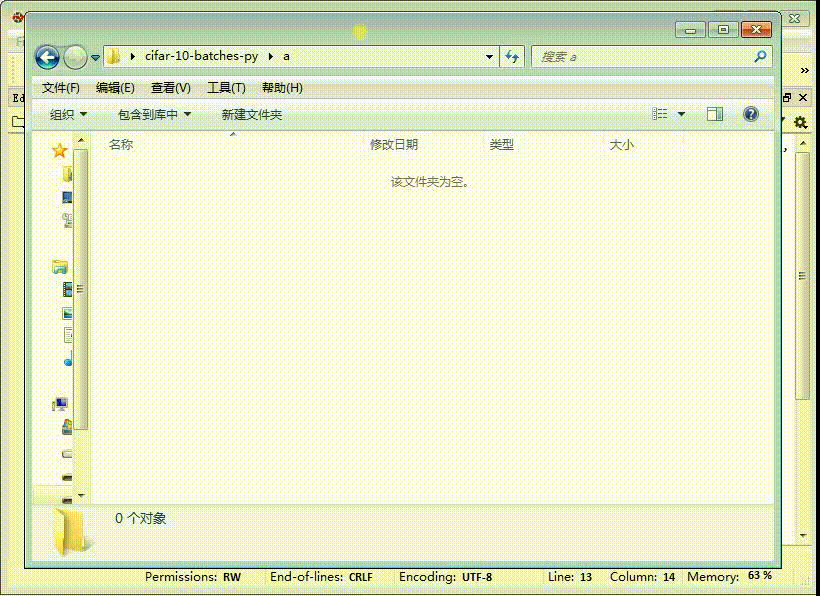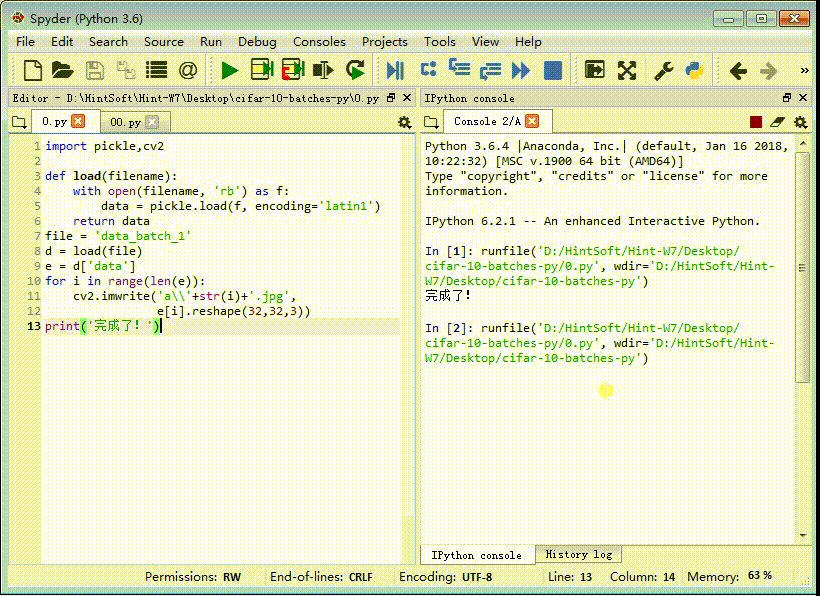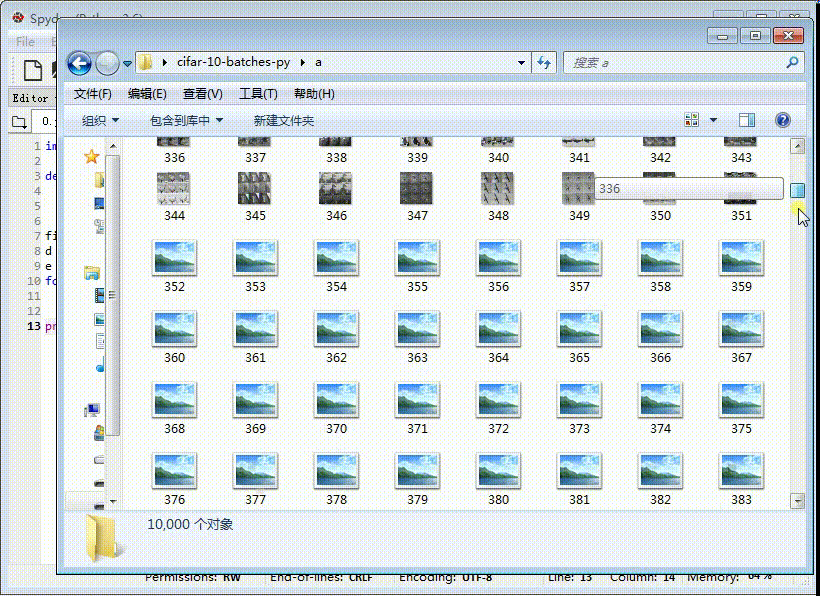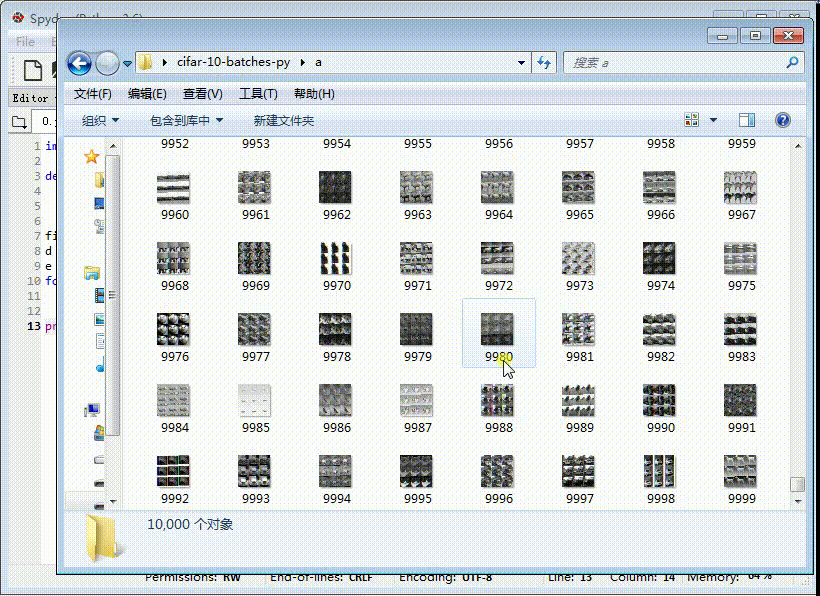
3、我们用咸菜模块来读取数据:# -*- coding: utf-8 -*-import pickledef load(filename): with open(filename, 'rb') as fo: data = pickle.load(fo, encoding='latin1') return data把python代码保存到数据集所在的文件夹里面。

4、读取第一个训练集——data_batch_1:p = 'data_batch_1'd = load(p)

5、上面的d是一个字典,我尺攵跋赈们来查看一下这个字典的关键字:print(d.keys())一共有四个关键字:'batch_label', 'labels', &#泌驾台佐39;data', 'filenames'

6、查看d的标签:'batch_label'运行结果是:training batch 1 of 5

7、查看d里面的各个数据的标签:print(d['labels'])这些标签是0到9之间的正整数。

8、查看d里面的图片的名称:print(d['filenames'])这些图片全都是png格式。

9、数据集的主体部分,是图片数据:print(d['data'])里面包含着10000张图片。

10、把这10000张图片数据还原为图片:e = d['data']for i in range(len(髫潋啜缅e)): cv2.imwrite('a\\'+str(i)+'.jpg', e[i].reshape(32,32,3))