1、首先去下载我准备的数据 http://pan.baidu.com/s/1bns3wwJ部分数据示例如下:

2、首先要建表,建表语句如下(无分区时)create table tmp.hive_sum (id string COMMENT '会员ID',bank_name string COMMENT '银行名称',create_time string COMMENT '交易时间',amount double COMMENT '交易金额') COMMENT 'hive_sum顶级应用'ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LINES TERMINATED BY '\n';
3、建表时要注意字段类型,根据数据发现,第一列是一串数字,这时第一列的字段类型可以为string,也可以为bigint,如果写成double的话也不会报错,不过类型跟你想要的就不一样了,写成int就会显示为null;为int时load结果
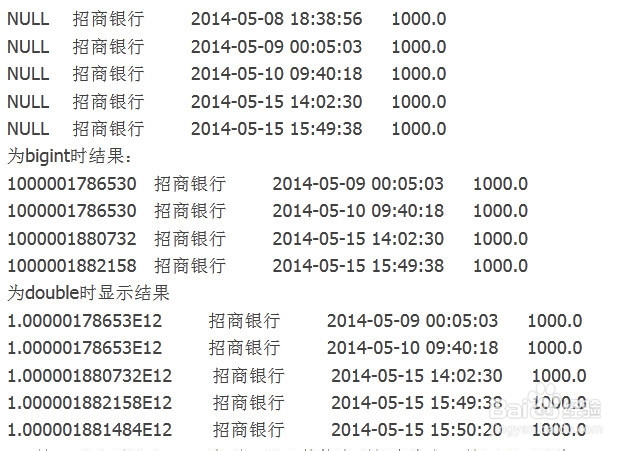
4、第二列必须写成string类型,写成其他类型就会为空;第四列可以为string,或者double,写成int或者bigint也不会报错,不过数据会被截断第三列int效果如下:

5、ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’这段的意思是字段与字段之间用\t分割,所以load数据之前要看看你文件的分割符是不是\t,如果不是就会出错,后面很多null等着你哦。当 然分隔符你可以自己指定,可以是‘,’逗号,冒号‘:’等,不过特殊字符要转义哦,并且保证你要导入的文本字段分割跟你的分隔符想匹配,字段与字段直接除 分隔符外不要有其它符合哦。
6、LINES TERMINATED BY ‘\n’是指换行符用\n,这个一般都不会出错
7、load语句。load data local inpath ‘/data/tmp/tqc/hive_sum.txt’ overwrite into table tmp.hive_sum,local inpath是指你文件的上传目录,如果你的文件在hdfs上,就不要家‘local’字段了,’/data/tmp/tqc /hive_sum.txt’ 是指文件的绝对路径,当然你也可以写成相对路径(如果你足够自信的话)。overwrite into是指每次加载都覆盖原数据,如果不想覆盖的话,就去掉overwrite吧。
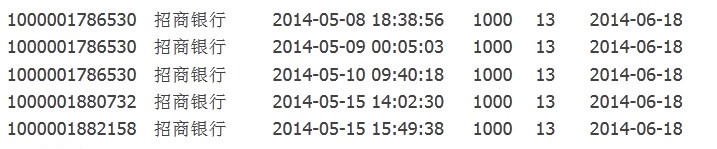
8、如果你要建分区表,只需加个分区字段就可以,可以有多个分区,code如下:create table tmp.hive_sum5 (id string COMMENT ‘会员ID’,bank_name string COMMENT ‘银行名称’,create_time string COMMENT ‘交易时间’,amount int COMMENT ‘交易金额’)COMMENT ‘hive_sum顶级应用’ partitioned by (hour int, dt string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’LINES TERMINATED BY ‘\n’;注意分区要写在表备注后面load语句同样发生了变化load data local inpath '/data/tmp/tqc/hive_sum.txt' overwrite into table tmp.hive_sum5 partition(hour=13,dt='2014-06-18');注意到没,多了partition(hour=13,dt=’2014-06-18′),partition字段一定要加的,hour和dt必须 写,如果你不指定分区的值,不好意思,不支持哦。你想指定成随机值,不好意思,load不可以,insert到是可以,不过要用动态分区,什么是动态分区 啊,百度吧先。结果如下
9、其它错误a.加载有乱码,那肯定是load文件格式跟你设定的格式不一样,load文本一般要设置成utf-8格式b.第一个字段是乱码,那怎么办?那是说明文本第一个字符那不是utf-8的,编辑模式下删掉第一个字符再敲上去,应该就可以了,在不行的话,重新导份上去吧
