1、加载pandas和urllib.request库中的urlretrieve包。从网站下载数据到本地。es_url和vs_url分别是从STOXX网站下载的2个数据的网址;urlretrieve表示直接将远程数据下载到本地的data目录下,分别命名为es.txt和vs.txt;如图所示


2、数据处理(删除空格)。lines=open('C:/Users/***/Documents/data/es.txt','r').readlines()表示读取文件到lines;lines=[line.replace(' ','') for line in lines]表示删除lines中的所有空格;lines[:6]表示展现lines的前6行数据;如图所示

3、数据检查(分号多余)。for line in lines[3883:3890]: print(line)表示查看lines的3884~3890的数据,发现最后几行多了一些‘;’,如图所示

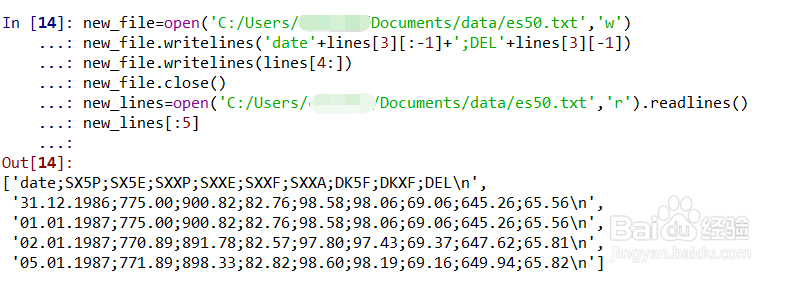
4、数据处理(分号处理:添加辅助列)。new_file=open('C:/Users/***/Documents/data/es50.txt','w')表示将要写入的新文件;new_file.writelines('date'+lines[3][:-1]+';DEL'+lines[3][-1])表示将lines的最后一列用缺失值填充,字段名为'DEL';new_file.writelines(lines[4:])表示从lines的第5行往后的数据写入新文件;new_file.close()表示关闭新文件;new_lines=open('C:/Users/***/Documents/data/es50.txt','r').readlines()表示打开新文件;new_lines[:5]表示查看前5行数据;如图所示
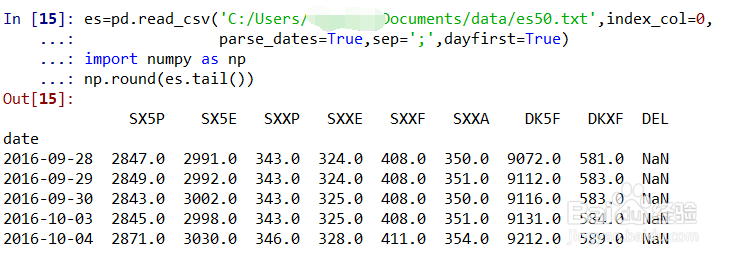
5、数据处理(格式处理)。es=pd.read_csv('C:/Users/***/Documents/data/es50.txt',index_col=0, parse_dates=True,sep=';',dayfirst=True)表示用read_csv导入txt文件的数据,index_col=0表示使用第一列为索引,parse_dates=True表示解析索引列日期,sep=';'表示分隔符是分号,dayfirst=True表示欧洲惯用日期格式DD/MM;加载numpy后,np.round(es.tail())查看es的后5行数据四舍五入后的情况;如图所示
6、数据处理(删除多余列:辅助列)。del es['DEL']表示删除多余的辅助列;es.info()表示删除后查看es的数据信息;如图所示

7、数据导入(第二种方法)。cols=['SX5P','SX5E','SXXP','SXXE','SXXF','SXXA','DK5F','DKXF']表示从上面看出来需要的列字段;es=pd.read_csv(es_url,index_col=0,parse_dates=True,sep=';',dayfirst=True, header=None,skiprows=4,names=cols)表示直接从网址下载数据,并导入,index_col=0表示第一列为索引列,parse_dates=True表示解析索引例如日期,sep=';'表示以分号分割,dayfirst=True表示使用欧洲惯用日期格式DD/MM,header=None表示标题行数量为空,skiprows=4表示跳过4行,names=cols表示用cols列表的字段作为列名;es.tail()表示查看es的最后5行数据,如图所示

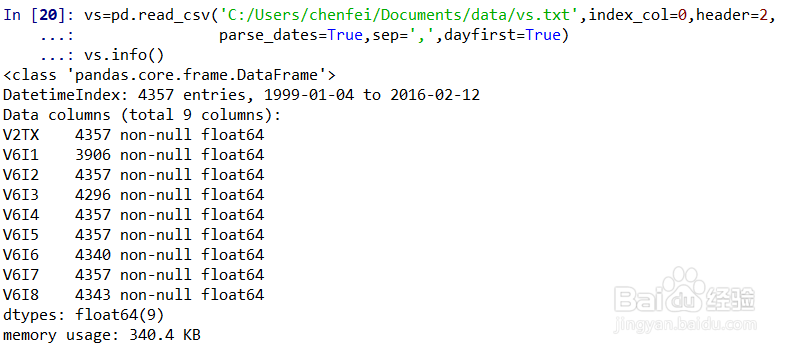
8、数据导入(另一个数据集)。vs=pd.read_csv('C:/Users/***/Documents/data/vs.txt',index_col=0,header=2, parse_dates=True,sep=',',dayfirst=True)表示读入数据集vs.txt,index_col=0表示使用第一列为索引,header=2表示标题行数量为2行,parse_dates=True表示解析索引例如日期,sep=','表示以逗号分隔,dayfirst=True表示使用欧洲惯用日期格式DD/MM;vs.info()表示查看vs的数据信息,如图所示