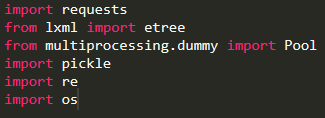
1、导入模块requests 用于获取网络请求etree 用于分析网页元素,提取需要的信息Pool 用于开启多线程,加快信息获取速率pickle 瓴烊椹舟将Python获取的信息存储在本地方便下次调用,避免多次获取重复数据re 正则表达式,匹配和提取网页中的信息os 用于创建文件夹等系统操作
2、获取所有老师的名字和其对应的主页网址get_actresses_list 从演员总页面获取演员名称和其主页网址,返回一个列表get_all忧溲枷茫_actress_list 通过多线程方式或前num页演员总页面的演员名称和其主页网址,最后通过pickle模块保存在本地

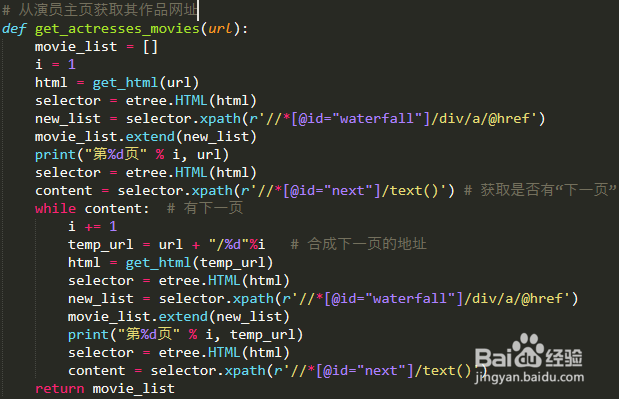
3、从老师主页获取影片编号和其影片的网址这里是判断当前页里是否有“下一页”,有就提取完当前页后跳转到下一页继续提取,直至提取所有影片
4、经过分析发现影片网页里的磁力链接是动态获取的,因此这里分两次请求,第一个获取影片网页,从中提取gid,第二次再向网站根据编号获取该影片的所有磁力链接,请求中还要带上第一次请求获取的gid

5、最后将所有步骤组合起来就是了
