知己知彼百战不殆,对于竞争对手或者目标消费群体的数据收集,我们乐此不疲。在IP代理盛行的今天,爬虫技术已经可以被我们充分发挥,海量收集数据,毫不手软。但是在爬虫采集的过程中会遇到反爬虫机制,那么Python爬虫怎么突破限制,实现数据的抓取呢?这是个难题!下面跟小编去了解一些Python爬虫架构组成,看看都有哪些限制,Python爬虫怎么突破限制。
一、Python爬虫架构组成
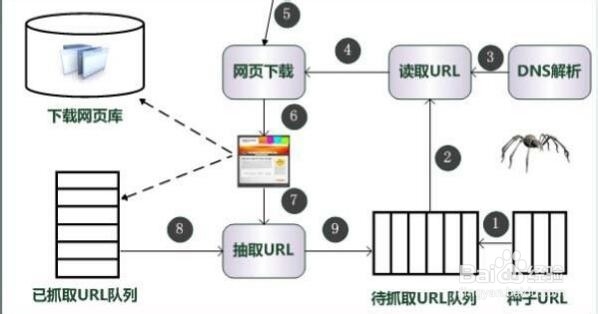
1、URL管理器管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器。网页下载器爬取url对应的网页,存储成字符串,传送给网页解析器。网页解析器解析出有价值的数据,存储下来,同时补充url到URL管理器。
二、Python爬虫怎么突破限制
1、IP限制如果是个人编写的爬虫,IP可能是固定的,那么发现某个IP请求过于频繁并且短时间内访问大量的页面,有爬虫的嫌疑,作为网站的管理或者运维人员,你可能就得想办法禁止这个IP地址访问你的网页了。那么也就是说这个IP发出的请求在短时间内不能再访问你的网页了,也就暂时挡住了爬虫。爬虫通常采用代理IP来突破限制,比如兔子代理,拥有全国海量IP,可以使用来突破IP的限制。验证码限制这个办法也是相当古老并且相当的有效果,如果一个爬虫要解释一个验证码中的内容,这在以前通过简单的图像识别是可以完成的,但是就现在来讲,验证码的干扰线,噪点都很多,甚至还出现了人类都难以认识的验证码。目前比较成熟的方法就是使用机器学习识别验证码内容。但是一旦验证码识别方式改动以后,这个着实是难以处理。但是大家也不要灰心,绕过验证码就一定要认认真真填写么?笔者在这里可以负责任地讲,验证码的绕过在很多的时候是通过web应用逻辑错误绕过的。
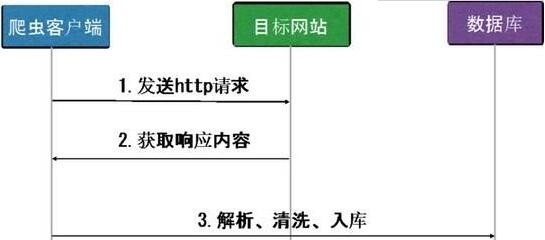
2、采集速度限制合理控制采集速度,是Python爬虫不应该破坏的规则,尽量为每个页面访问时间增加一点儿间隔,可以有效帮助你避免反爬虫。Cookie限制Cookie是一把双刃剑,有它不行,没它更不行。网站会通过cookie跟踪你的访问过程,如果发现你有爬虫行为会立刻中断你的访问,比如你特别快的填写表单,或者短时间内浏览大量页面。而正确地处理cookie,又可以避免很多采集问题,建议在采集网站过程中,检查一下这些网站生成的cookie,然后想想哪一个是爬虫需要处理的。兔子动态IP软件可以实现一键IP自动切换,千万IP库存,自动去重,支持电脑、手机多端使用。