1、本文假设pytesseract已经安装,并且tesseract也已经在系统中。对于含有英文文字的图片,使用如图方式即可获取识别结果。

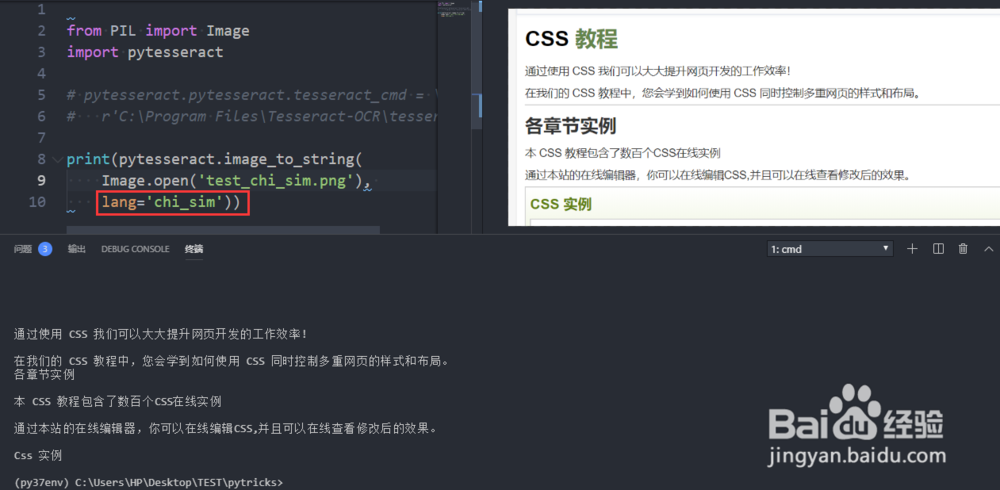
2、对于包含简体中文的图片,需要设定语言参数为chi_sim,如图所示,即可得到中文识别结果。
3、如果切换中文找不到traineddata文件,那么可能是安装时没有下载中文支持。可以查看如图安装目录查看文件是否存在。

4、image_to_string函数的第一个参数不一定要是Image.open的返回对象,也可以直接是表示图片文件路径的字符串,如图所示。

5、image_to_string函数的第一个参数还可以是一个文本文件,并在文本文件中列出所有要识别的图片文件。

6、如果要获取识别的所有character的边界框,使用image_to_boxes函数,如图所示。

7、如果需要查看更详细的识别结果,可以使用image_to_data函数。会给出字词识别的confidence等。

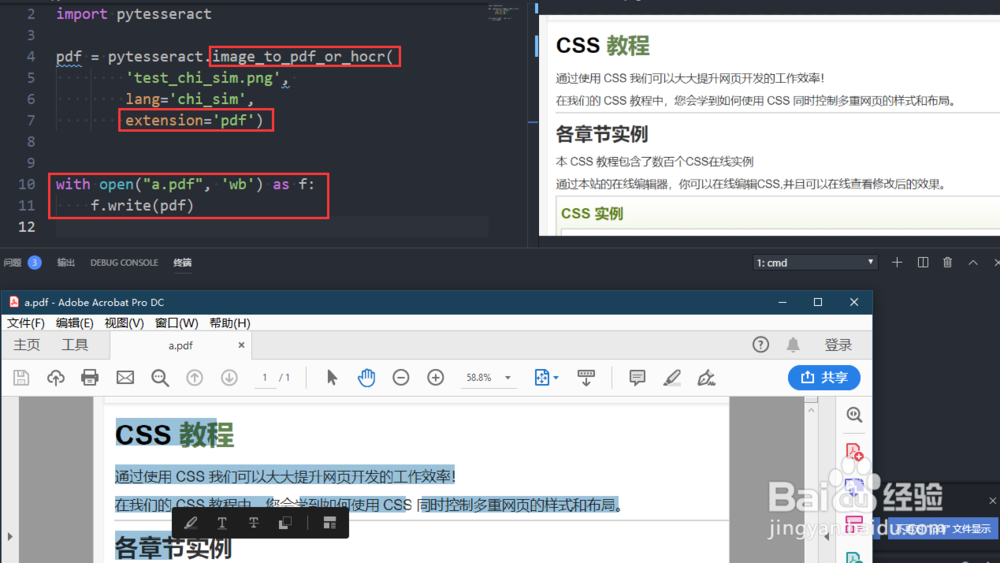
8、如果希望从图片生成可复制内容的pdf,使用image_to_pdf_or_hocr函数,并设定extension参数为pdf。
9、如果要查看识别的方向(orientation)和 Script Detection,需要使用image_to_osd函数,如图所示。

