大家都知道创世的页面天天改,但我们只要改下采集规则就成了。但后来发现创世加载章内容是通过js加载的了。通谷歌浏览器开发者工具我们可以看到在这个敌颉缪莽页面是通过AJAX加载的chuangshi.qq.com/read/Bookreader/1490356/0地址来输出章节内容的。入下图所示:
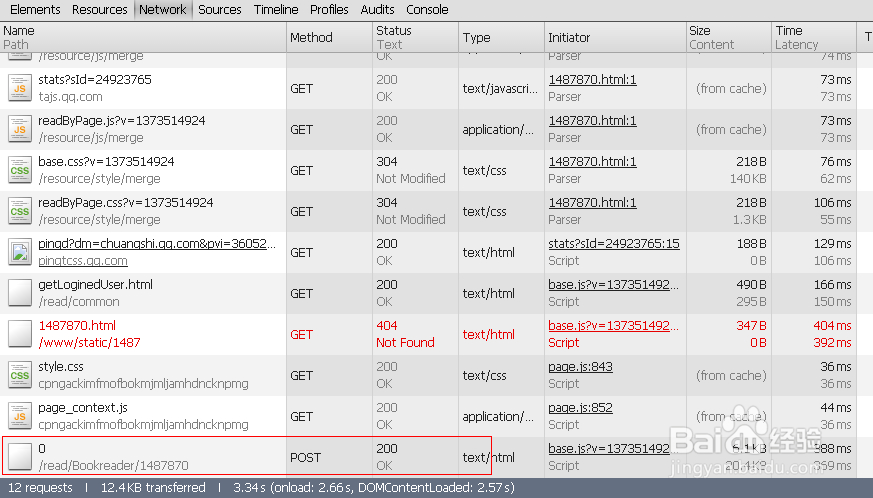
接下来我们打开这个页面可以看到都是一些乱七八糟的编码

其实像\u3000这种就是对汉字进行了Unicode编码。我仔细看了关关采集器也没找到怎么解决Unicode编码问题,后来想到一个解决办法,就是写了个小程序(一个动态页面)来根据传过来的ID号下载chuangshi.qq.com/read/Bookreader/ID号/0的内容,然后对其中的Unicode编码进行解码,然后输出。关关采集器就采集自己写的这个页面就行了。
具体方法,我不怎么会PHP只会.net所以就用.net做了个这个程序,很简单待会我会分享下。因为我是.net做的所以在我服务器上又新建了个小网站,当然不提供对外访问了。建好后访问我写的解码那个页面,后面传入名字为ID的章节号如图:
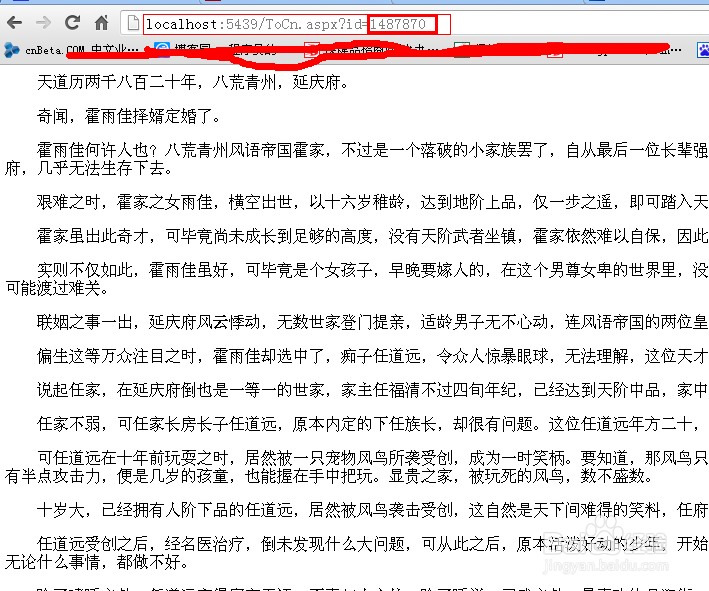
这样就获得干干净净的章节内容了。
最后在关关采集器中章节内容的地址换上自己的这个页面地址就行了,比如我的是http://127.0.0.1:8088/ToCn.aspx?id={ChapterKey}这样就行了,当然这个办法也不是只针对创世的,比如起点的章节页面UTF-8编码的,但他加载章节内容是通过js加载的一个txt文档,但这个文档是GB2312的,如果用关关的话就只能采集到一堆乱码,所以我们也可以通过这个方法自己的网站中一个页面做下代理,然后采集自己的页面就行了。
电脑软件
