1、方法是通过获取两字符串的前缀集合和后缀集合,其交集即为两者共有的前缀后者后缀,最长的一个,即为两者的最大重叠区域。代码如下:def overlap(s,t): prefits=set() postfits=set() prefitt=set() postfitt=set() for i in range(1,len(s)+1): prefits.add(s[:i]) for i in range(len(s)): postfits.add(s[i:]) for i in range(1,len(t)+1): prefitt.add(t[:i]) for i in range(len(t)): postfitt.add(t[i:]) result=list((prefits&postfitt)|(postfits&prefitt)) if len(result)==0: return -1 else: max_overlap=result[0] max_length=len(result[0]) for i in range(len(result)): if len(result[i])>max_length: max_length=len(result[i]) max_overlap=result[i] return max_overlap

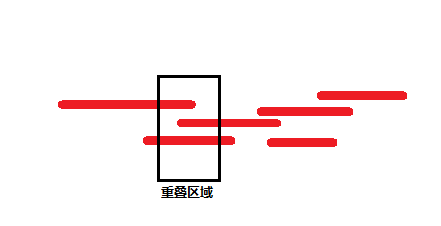
2、原理如下图:通过构建重叠群,拼接基因组结果如下:
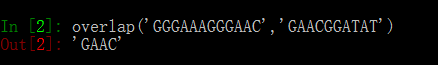
3、这是一个展示结果的方法其原理为求两者合并后的长度,并且在各自的位置匹配,显示重叠后的字符串def show_overlap(s,t): lcs=overlap(s,t) if lcs!=-1: length=len(s)+len(t)-len(lcs) if s.find(lcs)==0: s=' '*(length-len(s))+s else: t=' '*(length-len(t))+t return s+'\n'+t else: return -1

4、最终运行结果:

