1、准备好数据,在菜单栏上执行:analyse--classify--k-means cluster,打开k平均数对话框

2、将聚类用到的指标变量放入variables,将客户的编码放到label cases by当中,把客户编号作为case的标签

3、接着要设置聚类的类别数目,如图所示,这个数目不是随便给的,他有两个来源:要么是你根据工作经验,认为数据分为几类是最合理的;要么是你有前人的研究证明分为几类。

4、在主对话框中,点击iterate按钮,打开迭代对话框
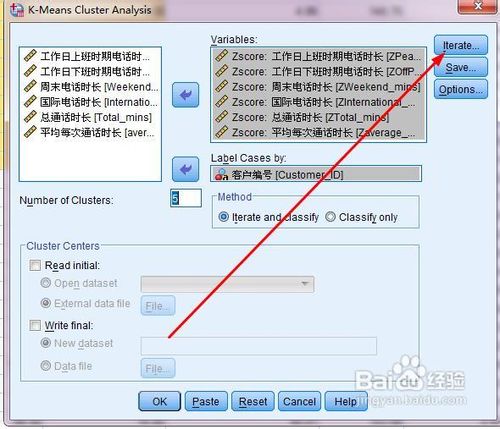
5、将最大迭代次数设置为100,下图你看到的默认的迭代次数为10,但是数据量越大,迭代次数就应该越多,所以我们设置为100.点击continue按钮,返回到主对话框。
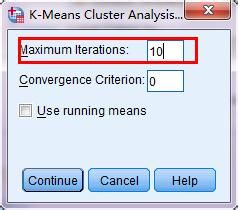
6、点击save按钮,因为我们想要保存分类的结果,并将结果保存到一个变量当中
7、打开一个自对话框,勾选cluster membership,点击continue返回到主对话框
8、点击ok,开始运行数据,并输出数据结果
9、我们看到的第一个表格叫做初始聚类中心,它列出每一个类别初始的中心点,这些中心点都是spss自动生成的。因为case的顺序会影响到中心点的位置,所以我们需要让case的顺序是随机的,有必要的时候要进行随机化处理

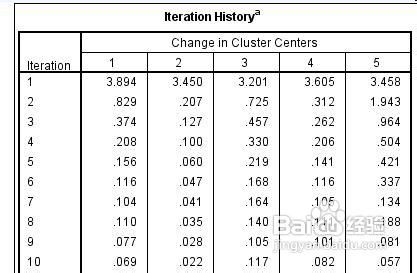
10、下面的两个表格是迭代过程釉涑杵抑表,你可以看到每一次迭代中心点的变化值,当中心点的变化小于初始类别中心最小距离的2%的时候,迭代就停止了,你看到的第二幅图在迭代35次以后就停止了迭代

11、下面这个表格叫做最终聚类中心,也就是各个类别在各个变量上的平均值,它可以帮助我们根据变量的平均值来给分类赋予实际的意义

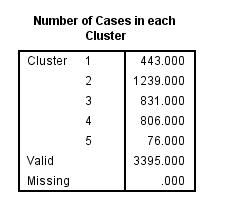
12、最后的表格叫做各个类别case数,你可以读出在每一个类别中有多少case