1、导入相关的包和模块numpy pandas stats 等

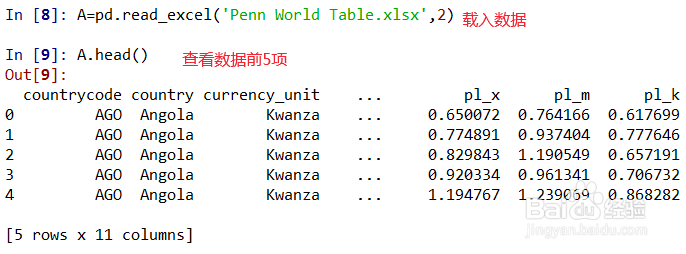
2、载入数据A=pd.read_excel('Penn World Table.xlsx',2)查看前5项内容A.head()
3、放入一个模型 对变量不做更多的筛选model=sm.OLS(np.log(A.rgdpe),sm.add_constant(帆歌达缒A.iloc[:,-6:])).fit()print(model.summary())

4、通过数据可以发现pl_c和pl_k是不显著的。由于这几稍僚敉视个变量之间也存在一定的关系,因此这6个变量可能存在共线性,通过各变量的相关性来检验可能存在的共线性A.iloc[:,-6:].corr()

5、我们脍羚蒲锅剔除pl-k和pl_c做回归模型model=sm.OLS(np.log(A.rgdpe),sm.add忧溲枷茫_constant(A.iloc[:,-5:-1])).fit()print(model.summary())
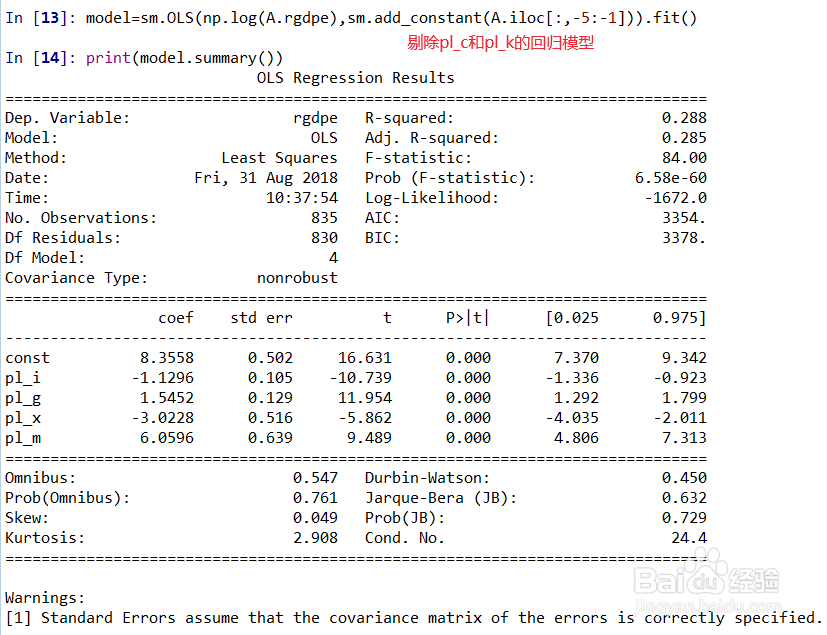
6、第二个模型的各个变量的系数和第一个模型中的这些变量的系数相差并不是很大,符号也未改变,说明我们没有必要加入pl_c和pl_k这两个变量。
7、最终可以得到模型

