1、下面我们逐一介绍,首先我们看一下第一种情况,也就是%在尾的这种情况。现场创建一张测试表t1,并将t1表灌入100万条测试数据。

2、前三个命里主要是设置格式和执行时间,最后一个命令主要是打开我们的执行计划跟踪
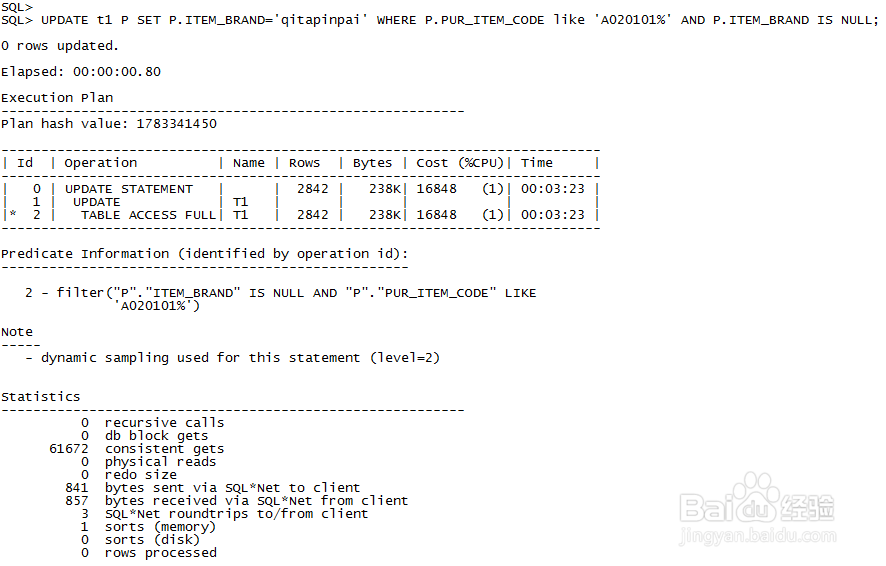
3、不用建索引,我们直接进行update操作,先看一下全表扫描情况的资源消耗情况,通过下图可以看到t1在update时全表扫描逻辑读达到61672
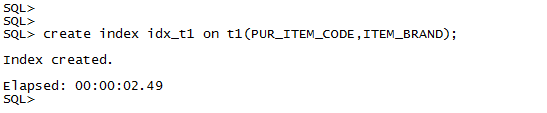
4、对于%在尾的这种情况,我们直接在where list中相应的字段创建索引。
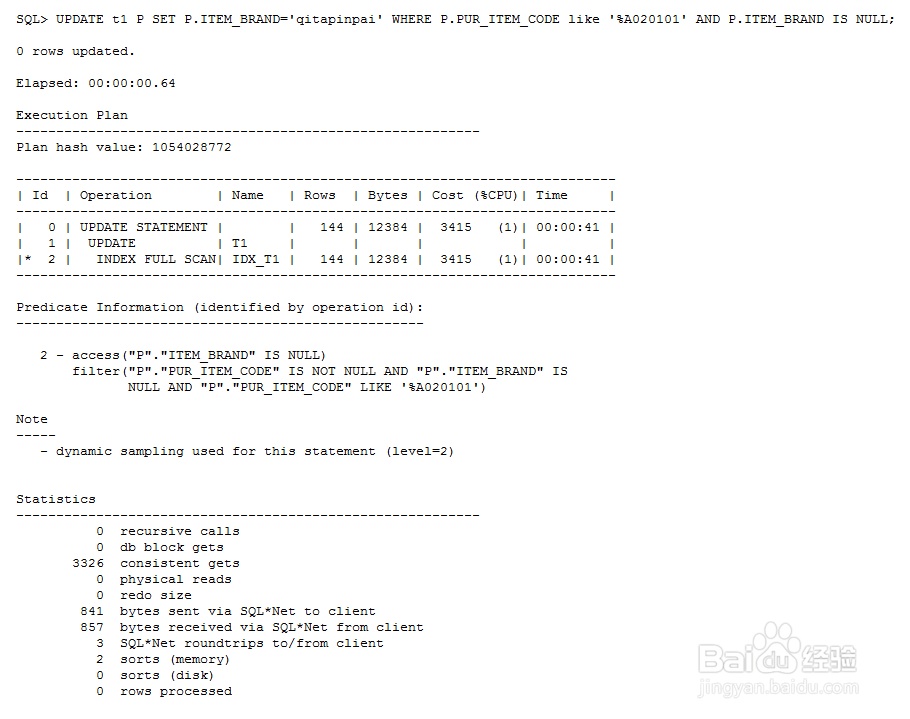
5、我们再次执行同样的update操作,观察一下该sql的执行计划,通过下图可以看到t1在update时已经选取了我们的索引,而且逻辑读只有650

6、接下来我们看一下第二种情况,也就是%在头的这牡啾锯辏种情况。依然是执行update语句。可以看到这种情况下,oracle优化器选择了我们刚才创建的索引,但是逻辑读仍有3000多,效果依然不理想。
7、下面我们创建反向索引

8、我们利用oracle的undocument函数reverse来使oracle优化器选择我们刚创建的反向索引,观察一下盐淬芪求该sql的执行计划,通过下图可以看到t1在update时已经选取了我们的反向索引,而且逻辑读只有3
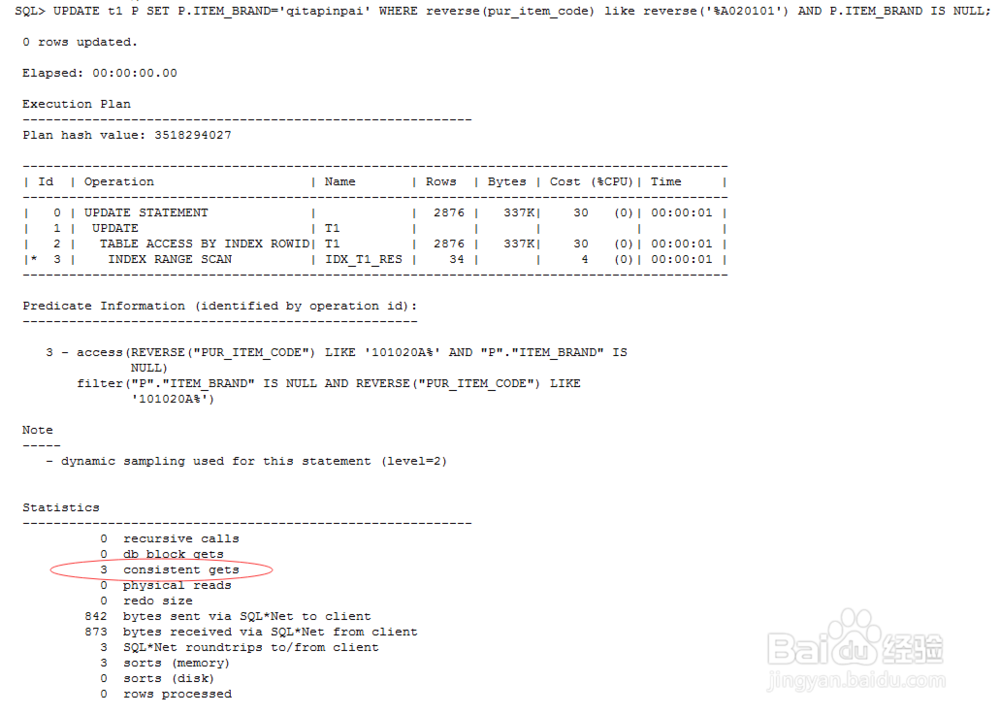
9、最后介绍一下两头都有%这种情况,一般这种情况,我们使用instr函数来替代like,但是根据下图显示,oracle优化器选择了全表扫描,效果肯定不理想。
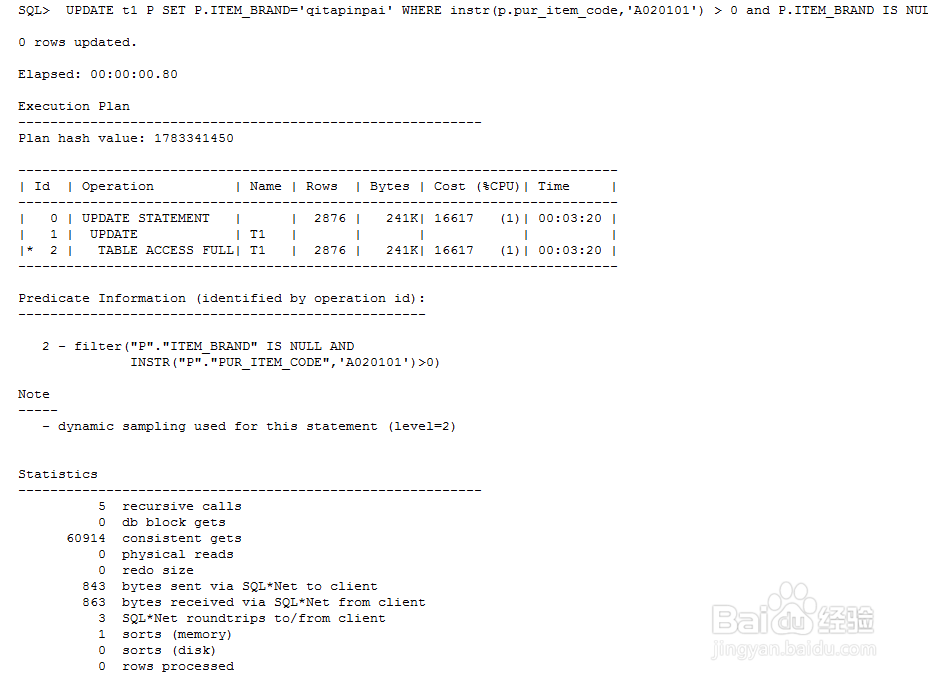
10、此时我们创建函数索引

11、再次执行update,通过下图可见,oracle优化器已经利用我们创建的函数索引,效果也比like‘%%’好的多。

