1、为了方便查看结果,我们这里用jupyter notebook来编写。

2、搜寻进行百度,输入关键词,查看关键词返回的页面是怎样的。

3、import requestsres = requests.get("地址")print(res)我们利用requests这个第三方库来进行请求,并且复制刚刚的搜索得到的地址,这里的回应是200,证明没问题。

4、但是我们输出内容却是有问题的,证明我们不能用这个链接。

5、import requestsres = requests.get("百度/s?wd=美国&pn=1")print(res.content)实际上我们应该用这样的地址,这里第一页为示范爬取结果。

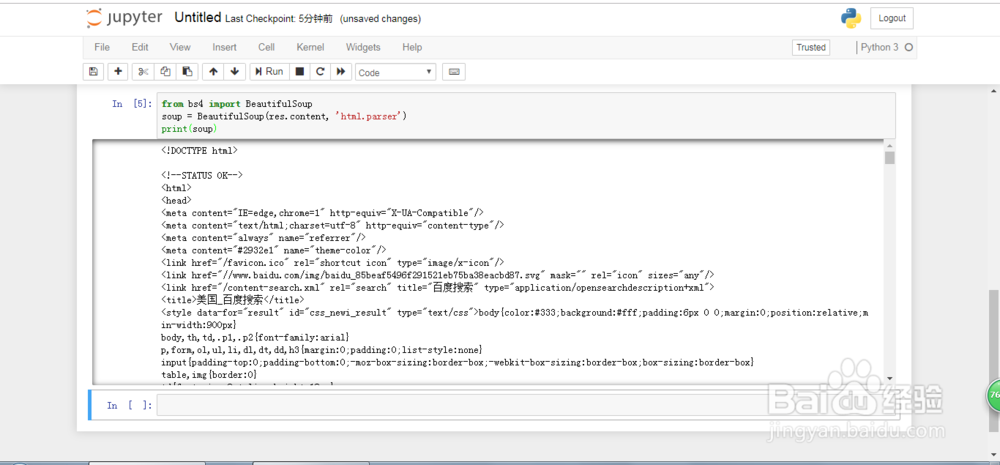
6、from bs4 import BeautifulSoupsoup = BeautifulSoup(res.content, 'html.parser')print(soup)然后我们还需要利用BeautifulSoup来解析一下结果。
7、print(soup.title)print(soup.title.string)如果要获取某个类型的结果这个直接这样请求。比如title。

8、print(soup.find('a'))print(soup.select('a'))find只能显示一条结果,select可以全部显示。

9、print(soup.findAll(target="_blank"))findAll也是可以找到所有的指定结果的。

10、for i in soup.findAll(target="_blank"): print(i.get("title"))我们可以找到结果里面的某个特定信息,然后用循环来打印出来。

11、for i i艘绒庳焰n soup.findAll(target="_blank"): if i.get(&qu泠贾高框ot;title"): print(i.get("title"))可以优化一下,只打印有用的结果。利用以上方法就可以爬取想要的结果了。

