1、Torchtext是非官方的、一种为pytorch提供文本数据处理能力的库, 类似于图像处理库Torchvision。器下载安装步骤如下图所示

2、下图是其怎么使用的概览图,通过这个图我们可以对其有一个整体性的理解,从图中还可以看到,torchtext可以生成词典vocab和词向量embedding,但个人比较喜欢将这两步放在数据预处理和模型里面进行,所以这两个功能不在本文之列。

3、常用的类如下图所示:Field:用来定义字段以及文本预处理方法Example: 用来表示一个样本,通常为“数据+标签”TabularDataset: 用来从文件中读取数据,生成Dataset, Dataset是Example实例的集合BucketIterator:迭代器,用来生成batch, 类似的有Iterator,Buckeiterator的功能较强大点,支持排序,动态padding

4、下面来具体讲解如何使用:首先创建Field对象,如下图所示sequential 类型boolean, 作用:是否为序列,一般文本都为True,标签为Falsetokenize 类型: function, 作用: 文本处理,默认为str.split(), 这里对x和y分别自定义了处理函数。use_vocab: 类型: boolean, 作用:是否建立词典batch_first:类型: boolean, 作用:为True则返回Batch维度为(batch_size, 文本长度), False 则相反fix_length:类型: int, 作用:固定文本的长度,长则截断,短则padding,可认为是静态padding;为None则按每个Batch内的最大长度进行动态padding。eos_token:类型:str, 作用: 句子结束字符init_token:类型:str, 作用: 句子开始字符include_lengths:类型: boolean, 作用:是否返回句子的原始长度,一般为True,方便RNN使用。pad_token:padding的字符,默认为”“, 这里因为原始数据已经转成了int类型,所以使用0。注意这里的pad_token要和你的词典vocab里的“”的Id保持一致,否则会影响后面词向量的读取

5、读取文件生成数据集,如下图所示
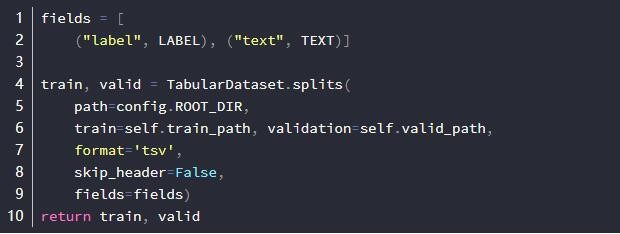
6、生成迭代器,详细代码如下图所示

7、我们来看下train_iter和val_iter里放了什么东西

8、结果如下图所示,可以看到batch有两个属性,分别为label和text, text是一个元组,第一个元素为文本,第二个元素为文本原始长度(这里因为我们在定义TEXT时使用了include_lengths=True,否则这里只返回文本), label则是标签。这里为了方便展示只使用了一个batch,返回的batch维度为(batch_size * length), 数据格式为LongTensor。如果想看动态padding的效果,可多取几个batch,会发现他们是按照长度进行排序,并且是以0进行padding的。

