1、安装Scrapy:pip install Scrapy

2、创建一个项目:scrapy startproject tutorial(到指定目录下在终端执行该命令)

3、创建成功后,将会显示如下图内容:

4、我的第一个爬虫Demo:import scrapyclassQuotesSpider(scrapy.Spider): name = "quotes" def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
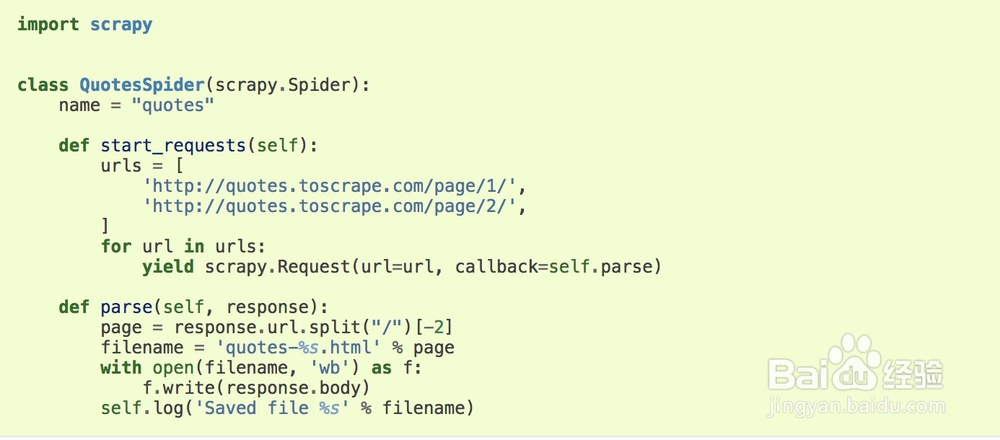
5、运行我的爬虫:scrapy crawl quotes
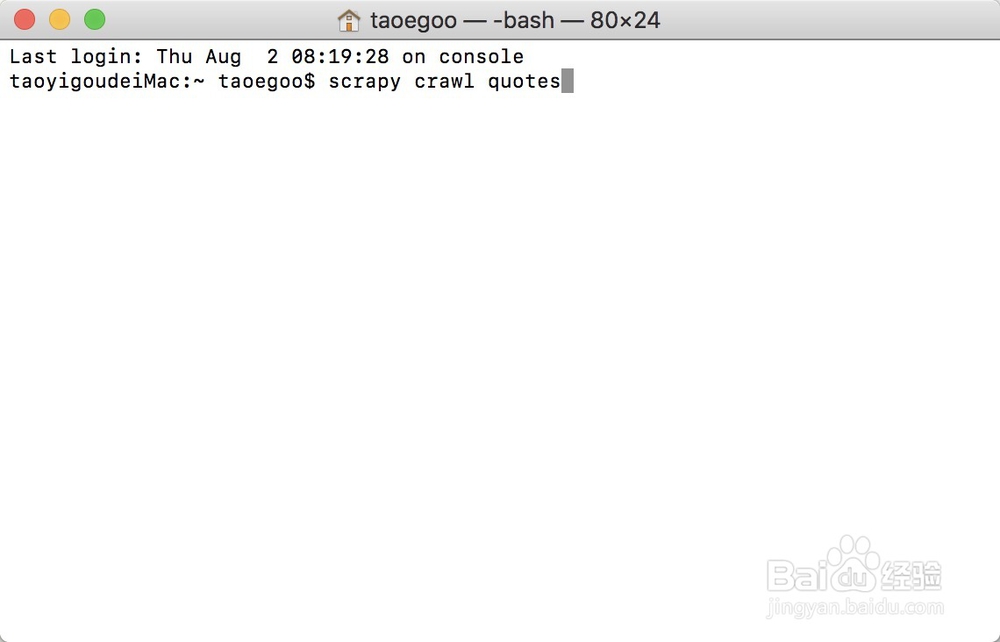
6、运行结果大体如下图所示:

