1、先搜寻文库,打开文库中所需要的某些文字。为了文字识别率高,请最好点击如图示的“全屏”按钮。

2、依次点击“开始→所有程序→附件→截图工具”,拖动光标选取要捕获的区域,然后点击“保存”图标。


3、打开“汉王 PDF OCR”识别软件,点击软件上方快捷菜单的“浏览文件”图标按钮,找到刚才截取的图片文件“捕获.jpg”,点击“打开”按钮。

4、点击软件上方快捷菜单的“+”图标,把图片文件放大到合适大小。

5、点击软件上方快捷菜单的“版面分析”图标后,再点击“开始识别”图标。

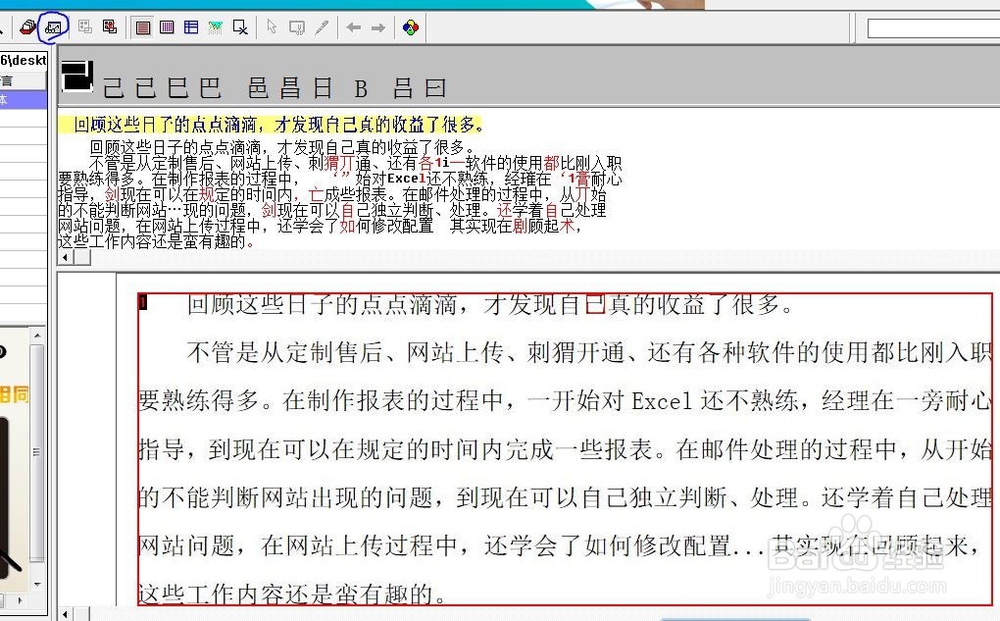
6、这时识别框分为上下两框,上框出现识别后的文字,软件认为识别模糊的字标记为红字,并列出了候选文字,可选择或自行修改。
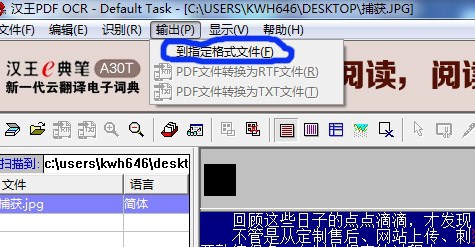
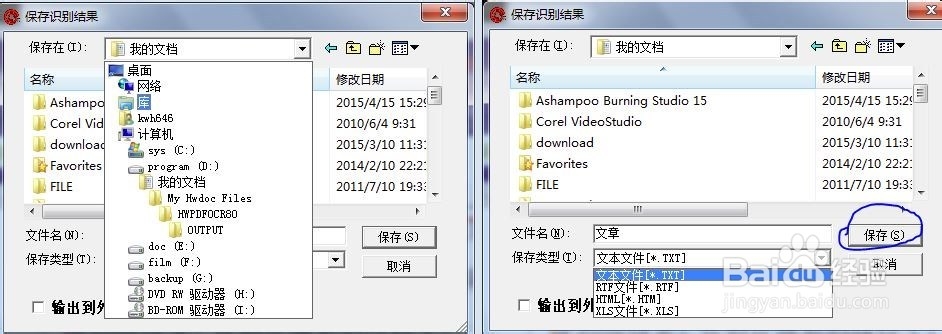
7、文字识别后,依次选择菜单栏中“输出→到制定格式文竭惮蚕斗件”,弹出保存对话框,选择文件夹,指定文件名,可以保存为“TXT、RTF、HTM、XLS”四种格式的文件。
8、打开刚刚保存的“文章.txt”,大功告成。