1、我们知道,http协议共有8种方法,真正的浏览器至少支持两种请求网页的方法:GET和POST。

2、相对于urllib2而言,urllib模块只接受字腿发滏呸符串参数,不能指定请求数据的方法,更无法设置请求报头。因此,urllib2被视为爬取数据所用“浏览器”的首选。

3、urllib2.urlopen除了可以接受字符串参数,还可以接受urllib2.Request对象。这意味着,我们可以灵活地设置请求的报头(header)。
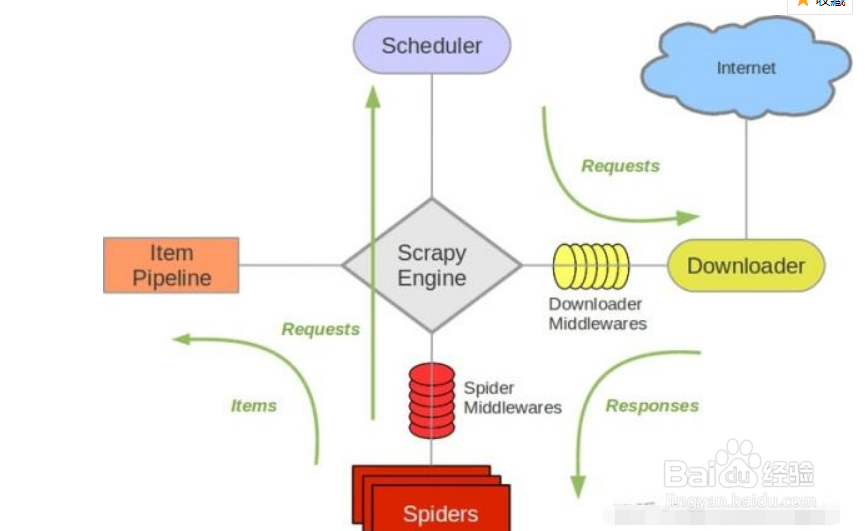
4、Beautiful Soup做为python的第三方库,可以帮助我们从网页源码中找到我们需要的数据。Beautiful Soup可以从一个HTML或者XML提取数据,它包含了简单的处理、遍历、搜索文档树、修改网页元素等功能。安装非常简单(如果没有解析器,也一并安装): pip install beautifulsoup4。

5、使用正则表达式解析数据 有时候,目标数据隐身于大段的文本中,无法透过html标签直接获取;或者,相同的标签数量众多,而目标数据只占其中的一小部分。

6、此时一般要借助于正则表达式了。下面的代码可以直接把年月日提取出来(提示:处理中文时,html源码和匹配模式必须使用utf-8编码,否则运行出错) 。

