多项式朴素贝叶斯实现文本分类算法,在此算法中删除了样本数据中的标题,引用和尾部。
工具/原料
Jupyter
获取数据集
1、导入模块。

2、需要导出相关类别的新闻数据。

3、获取训练集和测试集数据。

探索数据集
1、训练集样本。

2、测试集样本。

3、训练集的特征数据标签。

4、训练集的特征数据标签名。

5、训练集的样本。

特征工程
1、分离训练集的特征数据和目标数据。

2、训练集样本数量。

3、测试集样本数量。

4、用训练集数据拟合TF-IDF。

5、特征工程。

创建多项式分类模型
1、实例化多项式分类。

训练模型
1、训练多项式分类模型。

对模型进行评估
1、对多项式分类模型进行评估。

模型的评估指标
1、模型的评估成绩。

2、对数似然指标。

3、传入测试集数据,用训练完毕的模型进行分类。

4、可视化预测结果方法。

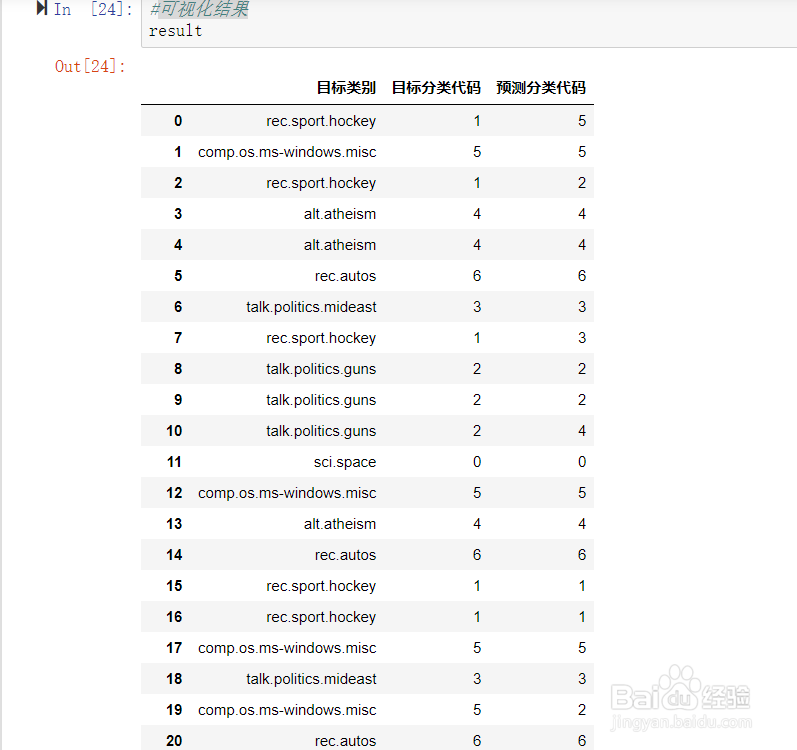
5、可视化结果。
6、测试样本数据量。

7、模型分类失误的数量。

8、模型的评估指标报告。

